A Python project got hacked where malicious releases were directly uploaded to PyPI. I said on Mastodon that had the project used trusted publishing with digital attestations, then people using a pylock.toml file would have noticed something odd was going on thanks to the lock file including attestation data
Content Preview
Since
trusted publishing
is a prerequisite for digital attestations, I'll cover that quickly. Basically you can set a project up on PyPI such that a continuous deployment (CD) system can upload a release to PyPI on your behalf. Since PyPI has to trust the CD system to do security right as it lets other sites upload to PyPI on your behalf, not every CD system out there is supported, but the big ones are and others get added as appropriate. Since this helps automate releases without exposing any keys to PyPI that someone might try to steal, it's a great thing to make your life as a maintainer easier while doing something safer; win-win!
So what can you do with this information once it's recorded in your pylock.toml? Well, the publisher details are stored for each package in the lock file. That lets code check that any files listed in the lock file for that package version were published from the same publisher that PyPI or whatever index you're using says the file came from. So if the lock file and index differ on where they say a file came from, something bad may have happened.
What can you do as a person if you don't have code to check that things line up (which isn't a lot of code; the lock file should have the
index server for the package
, so you follow the
index server API
to get the digital attestation for each file and compare)? There are two things you can do manually. One, if you know that a project uses trusted publishing then that digital attestation details should be in the lock file (you can manually check by looking at the file details on PyPI); if it's missing or changed to something suspicious then something bad may have happened. Two, when looking at a PR to update your lock file (and
pylock.toml
was designed to be human-readable
), if digital attestation details suddenly disappear then something bad probably happened.
So to summarize:
Use trusted publishing if you're a maintainer
Upload digital attestations if you're a maintainer
Use lock files where appropriate (and I'm partial to
pylock.toml
😁)
If you're using
pylock.toml
have code check the recorded attestations are consistent
When reviewing lock file diffs (which you should do!), make sure the digital attestations don't look weird or were suddenly deleted
A special thanks to William Woodruff, Facundo Tuesca, Dustin Ingram, and Donald Stufft for helping to make trusted publishers and digital attestations happen.
It's been a while since I posted about WASI support in CPython! 😅 Up until now, most of the work I have been doing around WASI has been making its maintenance easier for me and other core developers. For instance, the cpython-devcontainer repo now provides a WASI
Content Preview
But the main reason I'm blogging today is that
PEP 816
was accepted! That PEP defines how WASI compatibility will be handled starting with Python 3.15. The key point is that once the first beta for a Python version is reached, the
WASI
and
WASI SDK
versions that will be supported for the life of that Python version will be locked down. That gives the community a target to build packages for since things built with the WASI SDK are not forwards- or backwards-compatible for linking purposes due to
wasi-libc
not having any compatibility guarantees.
With that PEP out of the way, the next big items on my
WASI todo list
are (in rough order):
Implement a subcommand to bundle up a WASI build for
distribution
In case you didn't hear, PEP 810 got accepted which means Python 3.15 is going to support lazy imports! One of the selling points of lazy imports is with code that has a CLI so that you only import code as necessary, making the app a bit
Content Preview
In case you didn't hear,
PEP 810
got accepted which means Python 3.15 is going to support lazy imports! One of the selling points of lazy imports is with code that has a CLI so that you only import code as necessary, making the app a bit more snappy at startup. A common example given is when you run
--help
you probably don't need all modules imported to make that work. But another use case for CLIs and lazy imports is subcommands where each subcommand very likely only needs a subset of modules to work.
How to make subcommands work with argparse
There's two ways to typically do subcommands in argparse. The old-fashioned way is with a dict that dispatches to a function based on the subcommand name that was specified on the terminal. An example of that which I wrote can be found in the stdlib.
The other approach is covered in the
argparse docs for subcommands
which involves setting a default value for a subparser for the subcommand.
Regardless of which approach you use, the key detail is that something stores the callable you want to use based on the chosen subcommand.
Why these approaches don't work with lazy imports
Subcommands for a CLI is a great use of lazy imports. By making the imports that are not universally needed lazy, you can avoid paying any extra cost for imports you don't care about for any specific subcommand. This is even easier to do when you put a subcommand's code in a separate module as you can just lazy import the main function to call in your
__main__.py
, e.g.
lazy from spam import main as spam_main
and then use
spam_main
as the function to call when the
spam
subcommand is called.
The problem is that
reification
(the act of making the lazy import do the actual import and become the object it's meant to be) is triggered by assignment. That means using the lazy import object as a value in a dict or passing it as an argument to anything in argparse triggers the import. And since you need to do all your wiring upfront for argparse to do its thing, all of your lazy imports will get triggered that you assign using either of the approaches I listed above for making subcommands work. But I think lazy imports for subcommands is worth the hassle of trying to find a solution.
Some solutions to this problem
To make this all play nicely with lazy imports, you need to either avoid touching the lazy import objects if you don't need to use them or you need a level of indirection. To avoid touching the objects, you can do something like turning the dict approach into using a
match
statement.
match context.subcommand:
case "spam":
spam_main(context)
Another way to do it is to wrap the lazy import object in a
lambda
so there's a layer of indirection between the object and the assigment.
I want to be upfront that this blog post is for me to write down some thoughts that I have on the idea of rewriting the Python Launcher for Unix from Rust to pure Python. This blog post is not meant to explicitly be educational or enlightening for others, but
Content Preview
I want to be upfront that this blog post is for me to write down some thoughts that I have on the idea of rewriting the Python Launcher for Unix from Rust to pure Python. This blog post is not meant to explicitly be educational or enlightening for others, but I figured if I was going to write this down I might as well just toss it online in case someone happens to find it interesting. Anyway, with that caveat out of the way...
I started working on the
Python Launcher for Unix
in
May 2018
. At the time I used it as my Rust starter project and I figured distributing it would be easiest as a single binary since if I wrote it in Python how do you bootstrap yourself in launching Python with Python? But in the intervening 7.5 years, a few things have happened:
I became a dad (that will make more sense as to why that matters later in this post)
All of this has come together for me to realize now is the time to reevaluate whether I want to stick with Rust or pivot to using pure Python.
Performance
The first question I need to answer for myself is whether performance is good enough to switch. My hypothesis is that the Python Launcher for Unix is mostly I/O-bound (specifically around file system access), and so using Python wouldn't be a hindrance. To test this, I re-implemented enough of the Python Launcher for Unix in pure Python to make
py --version
work:
$VIRTUAL_ENV
environment variable support
Detection of
.venv
in the current or parent directories
Searching
$PATH
for the newest version of Python
It only took
72 lines
, so it was a quick hack. I compared the Rust version to the Python version on my machine running
Fedora 43
by running
hyperfine
"py --version"
. If I give Rust an optimistic number by picking its average lower-bound and Python a handicap of picking its average upper-bound, we get:
3 ms for Rust (333 Hz)
33 ms for Python (30 Hz)
So 11x slower for Python.
But
when the absolute performance is fast enough to let you run the Python Launcher for Unix over 30 times a second, does it actually matter? And you're not about to run the Python Launcher for Unix in some tight loop or even in production (as it's a developer tool), so I don't think that worst-case performance number (on my machine) makes performance a concern in making my decision.
If I rewrote the Python Launcher for Unix in Python, could I get equivalent distribution channels? Substituting crates.io for PyPI makes that one easy. The various package managers also know how to package Python applications already, so they would take care of the bootstrapping problem of getting Python your machine to run the Python Launcher for Unix.
Add in the fact that I'm working towards prebuilt binaries for python.org and it wouldn't even necessarily be an impediment if the Python Launcher for Unix were ever to be distributed via python.org as well. I could imagine some shell script to download Python and then use it to run a Python script to get the Python Launcher for Unix installed on one's machine (if relative paths for shebangs were relative to the script being executed then I could see just shipping an internal copy of Python with the Python Launcher for Unix, but a quick search online suggests such relative paths are relative to the working directory). So I don't see using Python as being a detriment to distribution.
Maximizing the impact of my time
I am a dad to a toddler. That means my spare time is negligible and restricted to nap time (which is shrinking), or in the evening (which I can't code past 21:00, else I have really wonky dreams or I simply can't fall asleep due to my brain not shutting off). Now I know I should eventually get some spare time back, but that's currently measured in years according to other parents, and so this time restriction to work on this fun project is not about to improve in the near to mid-future.
This has led me, as of late, to look at how best to use my spare time. I could continue to grow my Rust experience while solving problems, or I could lean into my Python experience and solve more problems in the same amount of time. This somewhat matters if I decide that increasing the functionality of the Python Launcher for Unix is the more fun for me than getting more Rust experience at this current point of my life.
And if I think the feature set is the most important, then doing it in Python has a greater chance of getting external contribution from the Python Launcher for Unix's user base. Compare that to now where there have been 11 human
contributors
over the project's entire lifetime.
Conclusion?
So have I talked myself into rewriting the Python Launcher for Unix into Python?
I was writing some code where I was using httpx.get() and its params parameter. I decided to use a TypedDict for the dictionary I was passing as the argument since it was for a REST API, where the potential keys were fully known. I then ran Pyrefly over my
Content Preview
I was writing
some code
where I was using
httpx.get()
and its
params
parameter
. I decided to use a
TypedDict
for the dictionary I was passing as the argument since it was for a REST API, where the potential keys were fully known. I then ran
Pyrefly
over my code and got an unexpected error about how
"object" is not a subtype of "str"
. I had no
object
in my
TypedDict
, so I didn't understand what was going on. I tried
Pyright
and it also failed. I then tried
ty
and it passed! What?! I know ty takes a less strict approach to typing to support a more gradual approach, so I figured there was a strict typing thing I was doing wrong. I did some digging and I found out that a new feature of
TypedDict
solves the issue for me, and so I figured I would share what I learned.
Starting in Python 3.15 and
typing-extensions
today, there are two dimensions to
TypedDict
and how keys and their existence are treated. The first dimension is whether the specified keys in a
TypedDict
are all
required
or not (controlled by the
total
argument or
Required
and
NotRequired
on a per-key basis). This represents whether every key specified in your
TypedDict
must
be in the dictionary or not. So if you have a
TypedDict
of:
class OptionalOpen(typing_extensions.TypedDict, total=False):
spam: str
it means the "spam" key is optional. To make it required you just set
total=True
or
spam: Required[str]
:
class RequiredOpen(typing_extensions.TypedDict, total=True):
spam: str
This concept has been around since Python 3.8 when
TypedDict
was introduced, with
Required
and
NotRequired
added in Python 3.11.
But starting in Python 3.15, a second dimension has been introduced that affects whether the
TypedDict
is
closed
. By default, a dictionary that is typed to a
TypedDict
can have any optional keys that it wants. So with either of our example
TypedDict
above, you could have any number of extra keys, each with any value. So what is a type checker to do if you reference some key that isn't defined by the
TypedDict
? Since the arbitrary keys are legal, you assume the "worst", and that the value for the key is
object
as that's the base class of everything.
So, let's say you have a function that takes a
Mapping
of
str
keys and
str
values:
It turns out that if you try to pass in a dictionary that is typed to either of our
TypedDict
examples you get a type failure like this (this is from Pyright):
/home/brett/py/typeddict_typing.py
/home/brett/py/typeddict_typing.py:26:6 - error: Argument of type "OptionalOpen" cannot be assigned to parameter "data" of type "Mapping[str, str]" in function "func"
"OptionalOpen" is not assignable to "Mapping[str, str]"
Type parameter "_VT_co@Mapping" is covariant, but "object" is not a subtype of "str"
"object" is not assignable to "str" (reportArgumentType)
This happens because
Mapping[str, str]
only
accepts values of
str
, but with our
TypedDict
there is the possibility of some unspecified key having a value of
object
. As such, e.g. Pyright complains that you can't use an
object
where
str
is expected, since you can't substitute anything that inherits from
object
for a
str
(that's what the variance bit is all about in that error message).
So how do you solve this? You say the
TypedDict
cannot
have any keys that are not specified; it's
closed
via the
closed
argument introduced in PEP 728
(currently, there are no docs for this in Python 3.15 even though it's
implemented
):
class OptionalClosed(typing_extensions.TypedDict, total=False, closed=True):
spam: str
With that argument you tell the type checkers that unless a key is specified in the
TypedDict
, the key isn't allowed to exist. That means our example
TypedDict
will
only
ever have keys that have a
str
value since we only have one possible key and its type is
str
. As such, that makes it a
Mapping[str, str]
since the only key it can ever have has a value type of
str
.
class RequiredOpen(typing_extensions.TypedDict, extra_items=str):
spam: str
So now any dictionary that is typed to this
TypedDict
will be presumed to have
str
be the type for any keys that aren't
spam
. That then means our
TypedDict
supports the
Mapping[str, str]
type as the only defined key is
str
and we have said any other key will have a value type of
str
.
Why it took 4 years to get a lock files specification
(This is the blog post version of my keynote from EuroPython 2025 in Prague, Czechia.)We now have a lock file format specification. That might not sound like a big deal, but for me it took 4 years of active work to get us that specification. Part education, part therapy,
Content Preview
We now have a
lock file format specification
. That might not sound like a big deal, but for me it took 4 years of active work to get us that specification. Part education, part therapy, this post is meant to help explain what make creating a lock file difficult and why it took so long to reach this point.
What goes into a lock file
A lock file is meant to record
all
the dependencies your code needs to work along with how to install those dependencies.
That involves The "how" is
source trees
,
source distributions
(aka sdists), and
wheels
. With all of these forms, the trick is recording the right details in order to know how to install code in any of those three forms. Luckily we already had the
direct_url.json
specification
that just needed translation into
TOML
for source trees. As for sdists and wheels, it's effectively recording what an index server provides you when you look at a project's release.
The much trickier part is figuring what to install when. For instance, let's consider where your top-level, direct dependencies come from. In
pyproject.toml
there's
project.dependencies
for dependencies you always need for your code to run,
project.optional-dependencies
(aka extras), for when you want to offer your users the option to install additional dependencies, and then there's
dependency-groups
for dependencies that are not meant for end-users (e.g. listing your test dependencies).
But letting users control what is (not) installed isn't the end of things. There's also the
specifiers
you can add to any of your listed dependencies. They allow you to not only restrict what versions of things you want (i.e. setting a lower-bound and
not
setting an upper-bound if you can help it), but also when the dependency actually applies (e.g. is it specific to Windows?).
Put that all together and you end up with a graph of dependencies who edges dictate whether a dependency applies on some platform. If you manage to write it all out then you have
multi-use
lock files which are portable across platforms and whatever options the installing users selects, compared to
single-use
lock files that have a specific applicability due to only supporting a single platform and set of input dependencies.
Oh, and even getting the complete list of dependencies in either case is an NP-complete problem.
And it make makes things "interesting", I also wanted the file format to be written by software but readable by people, secure by default, fast to install, and allow the
locker
which write the lock file to be different from the
installer
that performs the install (and either be written in a language other than Python).
In the end, it all worked out (luckily); you can read the spec for all the nitty-gritty details about
pylock.toml
or
watch the keynote
where I go through the spec. But it sure did take a while to get to this point.
Why it took (over) 4 years
I'm not sure if this qualifies as the longest single project I have ever taken on for Python (rewriting the import system might still hold that record for me), but it definitely felt the most intense over a prolonged period of time.
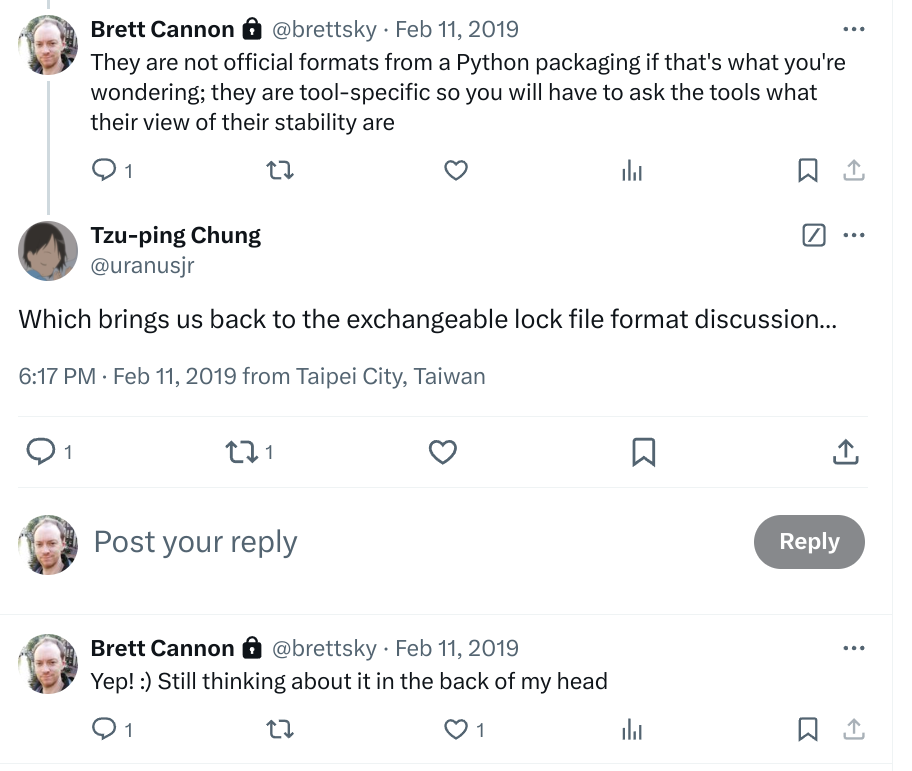
The oldest record I have that I was thinking about this problem is a tweet from Feb 2019:
2019
That year there were 106 posts on discuss.python.org about a
requirements.txt
v2 proposal. It didn't come to any specific conclusion that I can recall, but it at least got the conversation started.
2020
The next year, the conversation continued and generated 43 posts. I was personally busy with
PEP 621
and the
[project]
table in
pyproject.toml
.
2021
In January of 2021 Tzu-Ping Chung, Pradyun Gedam, and myself began researching how other language ecosystems did lock files. It culminated in us writing
PEP 665
and posting it in July. That led to 359 posts that year.
The goal of PEP 665 was a very secure lock file which partially achieved that goal by only supporting wheels. With no source trees or sdists to contend with, it meant installation didn't involve executing a build back-end which can be slow, be indeterminate, and a security risk simply due to running more code. We wrote the PEP with the idea that any source trees or sdists would be built into wheels out-of-band so you could then lock against those wheels.
2022
In the end,
PEP 665 was rejected
in January of 2022, generating 106 posts on the subject both before and after the rejection. It turns out enough people had workflows dependent on sdists that they balked at having the added step of building wheels out-of-band. There was also some desire to also lock the build back-end dependencies.
2023
After the failure of PEP 665, I decided to try to tackle the problem again entirely on my own. I didn't want to drag other poor souls into this again and I thought that being opinionated might make things a bit easier (compromising to please everyone can lead to bad outcomes when a spec if large and complicated like I knew this would be).
I also knew I was going to need a proof-of-concept. That meant I needed code that could get metadata from an index server, resolve all the dependencies some set of projects needed (at least from a wheel), and at least know what I would install on any given platform. Unfortunately a lot of that didn't exist as some library on PyPI, so I had to write a bunch of it myself. Luckily I had already started the journey before with my
mousebender
project, but that only covered the metadata from an index server. I still needed to be able to read
METADATA
files from a wheel and do the resolution. The former Donald Stufft had taken a stab at and which I picked up and completed, leading to
packaging.metadata
. I then used
resolvelib
to create a resolver.
As such there were only 54 posts about lock files that were general discussion. The key outcome there was trying to lock for build back-ends confused people too much, and so I dropped that feature request from my thinking.
2024
Come 2024, I was getting enough pieces together to actually have a proof-of-concept. And then
uv
came out in February. That complicated things a bit as it did/planned to do things I had planned to help entice people to care about lock files. I also knew I couldn't keep up with the folks at
Astral
as I didn't get to work on this full-time as a job (although I did get a lot more time starting in September of 2024).
I also became a parent in April which initially gave me a chunk of time (babies for the first couple of months sleep a lot, so if gives you a bit of time). And so in July I posted the first draft of
PEP 751
. It was based on
pdm.lock
(which itself is based on
poetry.lock
). It covered sdists and wheels and was multi-use, all by recording the projects to install as a set which made installation fast.
But uv's popularity was growing and they had extra needs that
PDM
and
Poetry
– the other major participants in the PEP discussions --didn't. And do I wrote another draft where I pivoted from a set of projects to a graph of projects. But otherwise the original feature set was all there.
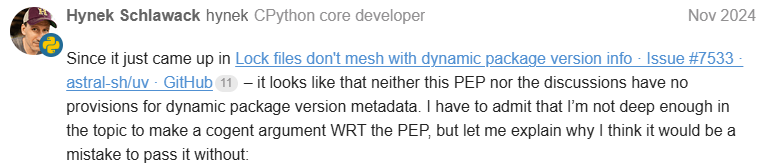
And then
Hynek
came by with what seemed like an innocuous request about making the version of a listed project optional instead of required (which was done because the
version
is required in
PKG-INFO
in sdists and
METADATA
in wheels).
Unfortunately the back-and-forth on that was enough to cause the Astral folks to want to scale the whole project back all the way to the
requirements.txt
v2 solution.
While I understood their reasoning and motivation, I would be lying if I said it wasn't disappointing. I felt we were extremely close up to that point in reaching an agreement on the PEP, and then having to walk back so much work and features did not exactly make me happy.
This was covered by 974 posts on discuss.python.org.
2025
But to get consensus among uv, Poetry, and PDM, I did a third draft of PEP 751. This went back to the set of projects to install, but was single-use only. I also became extremely stringent with timelines on when people could provide feedback as well as what would be required to add/remove anything. At this point I was fighting burn-out on this subject and my own wife had grown tired of the subject and seeing me feel dejected every time there was a setback. And so I set a deadline of the end of March to get things done, even if I had to drop features to make it happen.
And in February I thought we had reached and agreement on this third draft. But then Frost Ming, the maintainer of PDM, asked why did we drop multi-use lock files when they thought the opposition wasn't that strong?
And so, with another 150 posts and some very strict deadlines for feedback, we managed to bring back multi-use lock files and get PEP 751 accepted-- with no changes! -- on March 31.
2 PEPs and 6 years later ...
If you add in some ancillary discussions, the total number of posts on the subject of lock files since 2019 comes to over 1.8K. But as I write this post, less than 7 months since PEP 751 was accepted, PDM has already been updated to allow users to opt into using
pylock.toml
over
pdm.lock
(which shows that the lock file format works and meets the needs of at least one of the three key projects I tried to make happy). Uv and pip also have some form of support.
I will say, though, that I think I'm done with major packaging projects (work has also had me move on from working on packaging since April, so any time at this point would be my free time, which is scant when you have a toddler). Between
pyproject.toml
and
pylock.toml
, I'm ready to move on to the next area of Python where I think I could be the most useful.
PEP 750 introduced t-strings for Python 3.14. In fact, they are so new that as of Python 3.14.0b1 there still isn't any documentation yet for t-strings. 😅 As such, this blog post will hopefully help explain what exactly t-strings are and what
Content Preview
PEP 750
introduced t-strings for Python 3.14. In fact, they are so new that as of Python 3.14.0b1 there still isn't any documentation yet for t-strings. 😅 As such, this blog post will hopefully help explain what exactly t-strings are and what you might use them for by unravelling the syntax and briefly talking about potential uses for t-strings.
What are they?
I like to think of t-strings as a syntactic way to expose the parser used for
f-strings
. I'll explain later what that might be useful for, but for now let's see exactly what t-strings unravel into.
Let's start with an example by trying to use t-strings to mostly replicate f-strings. We will define a function named
f_yeah()
which takes a t-string and returns what it would be formatted had it been an f-string (e.g.
f"{42}" == f_yeah(t"{42}")
). Here is the example we will be working with and slowly refining:
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
return t_string
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
actual = f_yeah(expected)
assert actual == expected
As of right now,
f_yeah()
is just the identity function which takes the actual result of an f-string, which is pretty boring and useless. So let's parse what the t-string would be into its constituent parts:
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
return "".join(t_string)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = [
"Hello, ",
"world",
"! Conversions like ",
"'world'",
" and format specs like ",
"world ",
" work!",
]
actual = f_yeah(parsed)
assert actual == expected
Here we have split the f-string output into a list of the string parts that make it up, joining it all together with
"".join()
. This is actually what the bytecode for f-strings does once it has converted everything in the replacement fields – i.e. what's in the curly braces – into strings.
But this is still not
that
interesting. We can definitely parse out more information.
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
return "".join(t_string)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = [
"Hello, ",
name,
"! Conversions like ",
repr(name),
" and format specs like ",
format(name, "<6"),
" work!",
]
actual = f_yeah(parsed)
assert actual == expected
Now we have substituted the string literals we had for the replacement fields with what Python does behind the scenes with conversions like
!r
and format specs like
:<6
. As you can see, there are effectively three parts to handling a replacement field:
Evaluating the Python expression
Applying any specified conversion (let's say the default is
None
)
Applying any format spec (let's say the default is
""
)
So let's get our "parser" to separate all of that out for us into a tuple of 3 items: value, conversion, and format spec. That way we can have our
f_yeah()
function handle the actual formatting of the replacement fields.
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
converters = {func.__name__[0]: func for func in (str, repr, ascii)}
converters[None] = str
parts = []
for part in t_string:
match part:
case (value, conversion, format_spec):
parts.append(format(converters[conversion](value), format_spec))
case str():
parts.append(part)
return "".join(parts)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = [
"Hello, ",
(name, None, ""),
"! Conversions like ",
(name, "r", ""),
" and format specs like ",
(name, None, "<6"),
" work!",
]
actual = f_yeah(parsed)
assert actual == expected
Now we have
f_yeah()
taking the value from the expression of the replacement field, applying the appropriate conversion, and then passing that on to
format()
. This gives us a more useful parsed representation! Since we have the string representation of the expression, we might as well just keep that around even if we don't use it in our example (parsers typically don't like to throw information away).
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
converters = {func.__name__[0]: func for func in (str, repr, ascii)}
converters[None] = str
parts = []
for part in t_string:
match part:
case (value, _, conversion, format_spec):
parts.append(format(converters[conversion](value), format_spec))
case str():
parts.append(part)
return "".join(parts)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = [
"Hello, ",
(name, "name", None, ""),
"! Conversions like ",
(name, "name", "r", ""),
" and format specs like ",
(name, "name", None, "<6"),
" work!",
]
actual = f_yeah(parsed)
assert actual == expected
The next thing we want our parsed output to be is be a bit easier to work with. A 4-item tuple is a bit unwieldy, so let's define a class named
Interpolation
that will hold all the relevant details of the replacement field.
class Interpolation:
__match_args__ = ("value", "expression", "conversion", "format_spec")
def __init__(
self,
value,
expression,
conversion=None,
format_spec="",
):
self.value = value
self.expression = expression
self.conversion = conversion
self.format_spec = format_spec
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
converters = {func.__name__[0]: func for func in (str, repr, ascii)}
converters[None] = str
parts = []
for part in t_string:
match part:
case Interpolation(value, _, conversion, format_spec):
parts.append(format(converters[conversion](value), format_spec))
case str():
parts.append(part)
return "".join(parts)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = [
"Hello, ",
Interpolation(name, "name"),
"! Conversions like ",
Interpolation(name, "name", "r"),
" and format specs like ",
Interpolation(name, "name", format_spec="<6"),
" work!",
]
actual = f_yeah(parsed)
assert actual == expected
That's better! Now we have an object-oriented structure to our parsed replacement field, which is easier to work with than the 4-item tuple we had before. We can also extend this object-oriented organization to the list we have been using to hold all the parsed data.
class Interpolation:
__match_args__ = ("value", "expression", "conversion", "format_spec")
def __init__(
self,
value,
expression,
conversion=None,
format_spec="",
):
self.value = value
self.expression = expression
self.conversion = conversion
self.format_spec = format_spec
class Template:
def __init__(self, *args):
# There will always be N+1 strings for N interpolations;
# that may mean inserting an empty string at the start or end.
strings = []
interpolations = []
if args and isinstance(args[0], Interpolation):
strings.append("")
for arg in args:
match arg:
case str():
strings.append(arg)
case Interpolation():
interpolations.append(arg)
if args and isinstance(args[-1], Interpolation):
strings.append("")
self._iter = args
self.strings = tuple(strings)
self.interpolations = tuple(interpolations)
@property
def values(self):
return tuple(interpolation.value for interpolation in self.interpolations)
def __iter__(self):
return iter(self._iter)
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
converters = {func.__name__[0]: func for func in (str, repr, ascii)}
converters[None] = str
parts = []
for part in t_string:
match part:
case Interpolation(value, _, conversion, format_spec):
parts.append(format(converters[conversion](value), format_spec))
case str():
parts.append(part)
return "".join(parts)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = Template(
"Hello, ",
Interpolation(name, "name"),
"! Conversions like ",
Interpolation(name, "name", "r"),
" and format specs like ",
Interpolation(name, "name", format_spec="<6"),
" work!",
)
actual = f_yeah(parsed)
assert actual == expected
And that's t-strings! We parsed
f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
into
Template("Hello, ", Interpolation(name, "name"), "! Conversions like ", Interpolation(name, "name", "r"), " and format specs like ", Interpolation(name, "name", format_spec="<6")," work!")
. We were then able to use our
f_yeah()
function to convert the t-string into what an equivalent f-string would have looked like. The actual code to use to test this in Python 3.14 with an actual t-string is the following (PEP 750 has its own version of
converting a t-string to an f-string
which greatly inspired my example):
from string import templatelib
def f_yeah(t_string):
"""Convert a t-string into what an f-string would have provided."""
converters = {func.__name__[0]: func for func in (str, repr, ascii)}
converters[None] = str
parts = []
for part in t_string:
match part:
case templatelib.Interpolation(value, _, conversion, format_spec):
parts.append(format(converters[conversion](value), format_spec))
case str():
parts.append(part)
return "".join(parts)
if __name__ == "__main__":
name = "world"
expected = f"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
parsed = t"Hello, {name}! Conversions like {name!r} and format specs like {name:<6} work!"
actual = f_yeah(parsed)
assert actual == expected
What are t-strings good for?
As I mentioned earlier, I view t-strings as a syntactic way to get access to the f-string parser. So, what do you usually use a parser with? The stereotypical thing is compiling something. Since we are dealing with strings here, what are some common strings you "compile"? The most common answer are things like SQL statements and HTML: things that require some processing of what you pass into a template to make sure something isn't going to go awry. That suggests that you could have a
sql()
function that takes a t-string and compiles a SQL statement that avoids SQL injection attacks. Same goes for HTML and JavaScript injection attacks.
Add in logging and you get the common examples. But I suspect that the community is going to come up with some interesting uses of t-strings and their parsed data (e.g.
PEP 787
and using t-strings to create the arguments to
subprocess.run()
)!
I normally don't talk about politics here, but as I write this the US has started a trade war with Canada (which is partially paused for a month, but that doesn't remove the threat). It is so infuriating and upsetting that I will be skipping PyCon
Content Preview
I normally don't talk about politics here, but as I write this
the US has started a trade war with Canada
(which is partially
paused
for a month, but that doesn't remove the threat). It is so infuriating and upsetting that I will be skipping
PyCon US
entirely for the first time since 2003 to avoid giving any money to the US economy as a tourist (on top of just not feeling welcome in
a state that voted in Donald
, let alone in the US overall when Donald
won the popular vote
).
We have been told this is over fentanyl, but the
amount brought into the US through Canada is less than 1%
. Plus we spent CAD $1.3 billion on upping our border security and appointing a fentanyl czar that has led to a 97% decrease from Dec 2024 to Jan 2025. And all of this without the US doing something equivalent to try and lower the amount of
illegal guns flowing into Canada
.
No, this actually seems to be about trying to
cripple our economy to annex Canada
(no joke). The leader of one of the world's largest, most powerful armies simply cannot stop
talking about how they want to annex Canada
, which is not comforting (this is why Canadians have not found the "51st state" comment a joke whenever anyone makes it). Donald also can't seem to stand calling our prime minister by his proper title which is very disrespectful (hence why I keep using "Donald" in this post; I also refuse to use their preferred pronouns since trans lives matter and I doubt Donald would use anyone's preferred pronouns if they happened to disagree with them).
As
Warren Buffett said
, "Tariffs are ... an act of war, to some degree". As such, I just can't bring myself to voluntarily visit a country for fun that has started an economic war with my home country. This will be the first time I don't attend PyCon US physically or virtually since the conference was first named that in 2003, so I'm not making this decision lightly.
To be clear, I don't blame any Americans who voted for someone other than Donald. I view this as a decision of the current US government and the people who voted for Donald since they said, quite plainly on the campaign trail, that they were going to come after Canada.
So that means, for the foreseeable future, I will hope to see people at Python conferences and core dev sprints outside the US. It's a bit tricky to travel so far when our kid is still so young (not even 1 year old as I write this), but hopefully I can make something work at least on occasion to still see my friends in the Python community in person (luckily
PyCascades
is scheduled to be held in Vancouver in 2026).
Once all the tariffs are completely repealed (
pauses
don't count as that just makes it a looming threat), visiting
states that didn't vote for Donald
will be considered. But if I'm being honest, the way Canadians are reacting makes it feel like the Canada/US relationship has been damaged for at least a generation without a massive campaign on the US side to try and make amends. And that means any travel south of the border is going to be curtailed for a very long time.
When I was about to go on paternity leave, the Gleam programming language reached 1.0. It's such a small language that I was able to learn it over the span of two days. I tried to use it to convert a GitHub Action from JavaScript to Gleam,
Content Preview
When I was about to go on paternity leave, the
Gleam
programming language
reached 1.0
. It's such a small language that I was able to learn it over the span of two days. I tried to use it to convert a GitHub Action from JavaScript to Gleam, but I ran into issues due to Gleam wanting to be the top of the language stack instead of the bottom. As such I ended up
learning and using ReScript
. But I still liked Gleam and wanted to try writing something in it, so over the winter holidays I did another project with it from scratch.
Why Gleam?
First and foremost, their statement about community on their homepage spoke to me:
As a community, we want to be friendly too. People from around the world, of all backgrounds, genders, and experience levels are welcome and respected equally. See our community code of conduct for more.
Black lives matter. Trans rights are human rights. No nazi bullsh*t.
Secondly, the language is very small and tightly designed which I always appreciate (Python's "it fits your brain" slogan has always been one of my favourite tag lines for the language).
Third, it's a typed, functional,
immutable
language that is
impure
. I find that a nice balance of practicality while trying to write code that is as reliable as possible by knowing that if you get passed the compiler you're probably doing pretty well (which is good for projects you are not going to work on often but do have the time to put in the extra effort upfront to deal with typing and such).
Fourth, it compiles to either
Erlang
or JavaScript. Both have their (unique) uses which I appreciate (and in my case the latter is important).
I decided I wanted to create a website to help someone choose a coding font. When I was looking for one a while back I created screenshots of code samples which were anonymous so that I could choose one without undue influence (I ended up with
MonoLisa
). I figured it would be a fun project to create a site that did what I wish I had when choosing a font: a tournament bracket for fonts where you entered example text and then have fonts battle it out until you had a winner. This seemed like a great fit for Lustre and Gleam since it would be all client-side and have some interaction.
😅
It turns out
CodingFont
came out shortly before I started my project, unbeknownst to me. They take the same approach of a tournament bracket, but in a much prettier site with the bonus of being something I don't have to maintain. As such I won't be launching a site for my project, but the
code is available
in case you want to run your own tournament with your own choice of fonts.
The good
Overall, the language was a pleasure to work with. While the functional typing occasionally felt tedious, I knew there was benefit to it if I wanted things to work in the long-term with as little worry as possible that I had a bug in my code. The language was
nice and small
, and so I didn't have issue keeping it in my head while I coded (most of my documentation reading was for the
standard library
). And it was powerful enough with Lustre for me to need exactly
less than 200 lines of Gleam
to make it all work (plus less than 90 lines of static
HTML
and
CSS
).
The bad
I'm a Python fan, and so all the curly braces weren't my favourite thing. I know its for familiarity reasons and it's not going to cause me to not use the language in the future, but I wouldn't have minded less syntax to denote structure.
The other thing is having to specify a type's name twice for the name be usable as both the type and the constructor for a single record.
pub type Thingy {
Thingy(...)
}
Once again, it's very minor but something that I had to learn and typing the name twice always felt unnecessary and a typo waiting to happen for the compiler to catch. Having some shorthand like
pub record Thingy(...)
to represent the same thing would be nice.
The dream
I would love to have a WebAssembly/WASI and Python back-end for Gleam to go along with the Erlang and JavaScript one. I have
notes on writing a Python back-end
and
Dusty did a prototype
. Unfortunately I don't think the Gleam compiler – which written in Rust – is explicitly designed for adding more back-ends, so I'm not sure if any of this will ever come to pass.
Conclusion
I'm happy with Gleam! I'm interested in trying it with
Erlang
and the
BEAM
somehow, although my next project for that realm is with
Elixir
because
Phoenix LiveView
is a perfect fit for that project (I suspect there's something in Gleam to compete with Phoenix LiveView, but I do want to learn Elixir). But I definitely don't regret learning Gleam and I am still motivated enough to be working my way through
Exercism's Gleam track
.
In the past week I had two people separately tell me what they thought the Python Software Foundation Conduct WG did and both were wrong (and incidentally in the same way). As such, I wanted to clarify what exactly the WG does for people in case others also misunderstand what
Content Preview
In the past week I had two people separately tell me what they thought the
Python Software Foundation Conduct WG
did and both were wrong (and incidentally in the same way). As such, I wanted to clarify what exactly the WG does for people in case others also misunderstand what the group does.
⚠️
I am a member of the PSF Conduct WG (whose membership you can see by checking the
charter
), and have been for a few years now. That means I both speak from experience but I also may be biased in some way that I'm not aware of. But since this post is meant to be objective I'm hoping there aren't any concerns about bias.
🔔
There are a myriad of conduct groups in the Python community beyond the PSF Conduct WG, and they all work differently. For example, conferences like PyCon US have their own, the Django and NumFOCUS communities have their own, etc. This post is about a specific group and does
not
represent other ones.
I would say there are 4 things the Conduct WG actually does (in order from least to most frequent):
Let
PSF members
know when they have gone against the CoC in a public space
Record disciplinary actions taken by groups associated with the PSF
Provide conduct advice to Python groups
Let's talk about what each of these mean.
Maintain the CoC
In
September 2019 the CoC was rewritten
from a two paragraph "don't be mean" CoC to a more professional one. That rewrite actually is what led to the establishment of the Conduct WG in the first place. Since then, the Conduct WG is in charge of making any changes as necessary to the document. But ever since the rewrite was completed, it is rarely touched.
Let PSF members know when they have gone against the CoC publicly
Becoming a member of the PSF requires that you "
agree to the community Code of Conduct
". As such, if you are found to be running afoul of the CoC publicly where you also declare your PSF membership, then the Conduct WG will reach out to you and kindly let you know what you did wrong and to please not do that (technically you could get referred to the PSF board to have your membership revoked if you did something really bad, but I'm not aware of that ever happening).
But there are two key details about this work of the WG that I think people don't realize that are important. One is the Conduct WG does not go out on the internet looking for members who have done something that's in violation of the CoC. What happens instead is people report to the WG when they have seen a PSF member behave poorly in public while promoting their PSF membership (and this tends to be Fellows more than the general members).
Two, this is (so far) only an issue if you promote the fact that you're a PSF member. What you do in your life outside of Python is none of the WG's concern, but if you, e,g., call out your PSF affiliation on your profile on X and then post something that goes against the CoC, then that's a problem as that then reflects poorly on the PSF and the rest of the membership. Now, if someone were to very publicly come out as a member of some heinous organization even without talking about Python then that might be enough to warrant the Conduct WG saying something to the PSF board (and this probably applies more to Fellows than general members), but I haven't seen that happen.
Record CoC violations
If someone violates the CoC, some groups report them to the Conduct WG and we record who violated the CoC, how they violated, and what action was taken. The reason for this is to see if someone is jumping from group to group, causing conduct issues, but in a way that the larger pattern isn't being noticed by individual groups. But to be honest, not many groups report things (it is one more thing to do after dealing with a conduct issue which is exhausting on its own), and typically people who run afoul of the CoC where a pattern would be big enough to cause concern usually do it enough in one place as well, so the misconduct is noticed regardless.
Provide advice
The most common thing the Conduct WG does, by far, is provide advice to other groups who ask us for said advice based on the WG's training and expertise. This can range from, "can you double-check our logic and reaction as a neutral 3rd-party?" to, "can you provide a recommendation on how to handle this situation?"
While this might be the thing the Conduct WG does the most, it also seems to be the most misunderstood. For instance, much like with emailing PSF members when they have violated the CoC publicly while promoting their PSF membership, the Conduct WG does not go out looking for people causing trouble. This is entirely driven by people coming to the WG with a problem. The closest thing I can think of the Conduct WG doing in terms of proactively reaching out is some group that got a grant from the
PSF Grants WG
did something wrong around the CoC that was reported to the Conduct WG that warrants us notifying the Grants WG of the problem. But the Conduct WG isn't snooping around the internet looking for places to give advice.
I have also heard folks say the Conduct WG "demanded" something, or "made" something happen. That is simply not true. The Conduct WG has
no power
to compel some group to do something (i.e. things like moderation and enforcement is handled by the folks who come to the Conduct WG asking for advice). As an example, let's say the Python steering council came to the Conduct WG asking for advice (and that could be as open-ended as "what do you recommend?" to "we are thinking of doing this; does that seem reasonable to you?"). The Conduct WG would provide the advice requested, and that's the end of it. The Conduct WG
advised
in this hypothetical, it didn't
require
anything. The SC can choose to enact the advice, modify it in some way, or flat-out ignore it; the Conduct WG cannot make the SC do anything (heck, the SC isn't even under the PSF's jurisdiction, but that's not an important detail here, just something else I have heard people get wrong). And this inability to compel a group to do something even extends to groups that come to the Conduct WG for advice even if they
are
affiliated with the PSF. Going back to the Grants WG example, we can't make the Grants WG pull someone's grant or deny future grants, we can just let them know what we think. We can refer an issue to the PSF board, but we can't compel the board to do anything (e.g., if we warn a PSF member about their public conduct, we can't make them stop being a PSF member for it, the most we can do is inform the PSF board about what someone has done and potentially offer advice).
Having said all of that, anecdotally it
seems
that most groups that request a recommendation from the Conduct WG enact those recommendations. So you could say the Conduct WG was
involved
in some action that was taken based on the WG's recommendation, but you certainly cannot assign full blame on the WG for the actions taken by other groups either.
In my opinion, you should only introduce a named tuple to your code when you're updating a preexisting API that was already returning a tuple or you are wrapping a tuple return value from another API.Let's start with when you should use named tuples. Usually
Content Preview
In my opinion, you should only introduce a
named tuple
to your code when you're updating a preexisting API that was already returning a tuple or you are wrapping a tuple return value from another API.
Let's start with when you
should
use named tuples. Usually an API that returns a tuple does so when you only have a couple of items in your tuple and the name of the function returning the tuple is enough to explain what each item in the tuple does. But sometimes your API expands and you find that your tuple is no longer self-documenting purely based on the name of the API (e.g.,
get_mouse_position()
very likely has a two-item tuple of X and Y coordinates of the screen while
app_state()
could be a tuple of anything). When you find yourself in the situation of needing your return type to describe itself and a tuple isn't cutting it anymore, then that's when you reach for a named tuple.
So why not start out that way? In a word:
simplicity
. Now, some of you might be saying to yourself, "but I use named tuples because they are so simple to define!" And that might be true for when you
define
your data structure (and I'll touch on this "simplicity of definition" angle later), but it actually makes your API more complex for both you and your users
to use
. For you, it doubles the data access API surface for your return type as you have to now support index-based and attribute-based data access forever (or until you choose to break your users and change your return type so it doesn't support both approaches). This leads to writing tests for
both
ways of accessing your data, not just one of them. And you shouldn't skimp on this because you don't know if your users will use indexes or attribute names to access the data structure, nor can you guarantee someone won't break your code in the future by dropping the named tuple and switching to some custom type (thanks to Python's support of
structural typing
(aka duck typing), you can't assume people are using a type checker and thus the structure of your return type becomes your API contract). And so you need to test both ways of using your return type to exercise that contract you have with your users, which is more work than had you not used a named tuple and instead chose just a tuple or just a class.
Named tuples are also a bit more complex for users. If you're reaching for a named tuple you're essentially signalling upfront that the data structure is too big/complex for a tuple alone to work. And yet by using a named tuple means you
are
supporting the tuple approach even if you don't think it's a good idea from the start. On top of that, the tuple API allows for things that you probably don't want people doing with your return type, like slicing, iterating over all the items as if they are homogeneous, etc. Basically my argument is the "flexibility" of having the index-based access to the data on top of the attribute-based access isn't flexible in a good way.
So why do people still reach for named tuples when defining return types for new APIs? I think it's because people find them faster to define a new type than writing out a new class. Compare this:
Point = namedtuple('Point', ['x', 'y', 'z'])
To this:
class Point:
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z
So there is a clear difference in the amount of typing. But there are three more ways to do the same data structure that might not be so burdensome. One is
dataclasses
:
@dataclasses.dataclass
class Point:
x: int
y: int
z: int
Another is simply a
dictionary
, although I know some prefer attribute-based access to data so much that they won't use this option). Toss in a
TypedDict
and you also get editor support as well:
class Point(typing.TypedDict):
x: int
y: int
z: int
# Alternatively ...
Point = typing.TypedDict("Point", {"x": int, "y": int, "z": int})
A third option is
types.SimpleNamespace
if you really want attributes without defining a class:
Point = lambda x, y, z: types.SimpleNamespace(x=x, y=y, z=z)
If none of these options work for you then you can always hope that somehow I convince enough people that my
record/struct idea
is a good one and get into the language. 😁
My key point in all of this is to prefer readability and ergonomics over brevity in your code. That means avoiding named tuples except where you are expanding to tweaking an existing API where the named tuple improves over the plain tuple that's already being used.
I maintain a GitHub Action called check-for-changed-files. For the purpose of this blog post what the action does isn't important, but the fact that I authored it originally in TypeScript is. See, one day I tried to update the NPM dependencies. Unfortunately, that update broke
Content Preview
I maintain a
GitHub Action
called
check-for-changed-files
. For the purpose of this blog post what the action does isn't important, but the fact that I authored it originally in
TypeScript
is. See, one day I tried to update the
NPM
dependencies. Unfortunately, that update broke everything in a really bad way due to how the libraries I used to access PR details changed and howthe TypeScript types changed. I had also gotten tired of updating the NPM dependencies for security concerns I didn't have since this code was only run in CI by others for their own use (i.e. regex denial-of-service isn't a big concern). As such I was getting close to burning out on the project as it was a nothing but a chore to keep it up-to-date and I wasn't motivated to keep the code up-to-date since TypeScript felt more like a cost than a benefit for such a small code base where I'm the sole maintainer (there's only been one other contributor to the project since the
initial commit
4.5 years ago). I
converted the code base to JavaScript
in hopes of simplifying my life and it went better than I expected, but it still wasn't enough to keep me interested in the project.
And so I did what I needed to in order to be engaged with the project again: I rewrote it in
another programming language that could run easily under Node
. 😁 I decided I wanted to do the rewrite piecemeal to make sure I could tell if I was going to like the eventual outcome quickly rather than a complete rewrite from scratch and being unhappy with where I ended up (doing this while on parental leave made me prioritize my spare team immensely, so failing fast was tantamount). During my parental leave I learned
Gleam
because I loved their statement on expectations for community conduct on their homepage, but while it does compile to JavaScript I realized it works better when JavaScript is used as an escape hatch instead using Gleam to port an existing code base and so it wasn't a good fit for this use case.
My next language to attempt the rewrite with was
ReScript
thanks to my friend
Dusty liking it
. One of the first things I liked about the language was it had a
clear migration path from JavaScript to ReScript
in 5 easy steps. And since step 1 was "wrap your JavaScript code in
%%raw
blocks and change nothing" and step 5 was the optional "clean up" step, there was really only 3 main steps (I did have a hiccup with step 1, though, due to a
bug
not escaping backticks for
template literals
appropriately, but it was a mostly mechanical change to undo the template literals and switch to string concatenation).
A key thing that drew me to the language is its
OCaml
history. ReScript can have very strict typing, but ReScript's OCaml background also means there's type inference, so the typing doesn't feel that heavy. ReScript also has a functional programming leaning which I appreciate.
💡
When people say "ML" for "machine learning" it still throws me as I instinctively think they are actually referring to "
Standard ML
".
But having said all of that, ReScript does realize folks will be migrating or working with a preexisting JavaScript code base or libraries, and so it tries to be pragmatic for that situation. For instance, while the language has roots in OCaml, the
syntax
would feel comfortable to JavaScript developers. While supporting a functional style of programming, the language still has things like
if
/
else
and
for
loops
. While the language is strongly typed, ReScript as things like its
object
type
where the types of the fields can be inferred based on usage to make it easier to bring over JavaScript objects.
As part of the rewrite I decided to lean in on testing to help make sure things worked as I expected them to. But I ran into an issue where the first 3 testing frameworks I looked into didn't work with
ReScript 11
(which came out in January 2024 and is the latest major version as I write this). Luckily the 4th one,
rescript-zora
, worked without issue (it also happens to be by my friend, Dusty, so I was able to ask questions of the author directly 😁; I initially avoided it so I wouldn't pester him about stuff, but I made up for it by
contributing back
). Since ReScript's community isn't massive it isn't unexpected to have some delays in projects keeping up with stuff. Luckily the
ReScript forum
is active so you can get your questions answered quickly if you get stuck. But this hiccup and the one involving
%%raw
and template literals, the process was overall rather smooth.
In the end I would say the experience was a good one. I liked the language and transitioning from JavaScript to ReScript went relatively smoothly. As such, I have ported check-for-changed-files over to ReScript permanently in the 1.2.1 release, and hopefully no one noticed the switch. 🤞
After signing up for GitHub Sponsors, I had a nagging feeling that somehow asking for money from other people to support my open source work was inappropriate. But after much reflection, I realized that phrasing the use of GitHub Sponsors as a way to express patronage/support and appreciation for
Content Preview
After
signing up for GitHub Sponsors
, I had a nagging feeling that somehow asking for money from other people to support my open source work was inappropriate. But after much reflection, I realized that phrasing the use of GitHub Sponsors as a way to express patronage/support and appreciation for my work instead of sponsorship stopped me feeling bad about it. It also led me to reflect on to what degree people can express thanks to open source maintainers.
⚠️
This blog post is entirely from my personal perspective and thus will not necessarily apply to every open source developer out there.
Be nice
The absolutely easiest way to show thanks is to simply not be mean. It sounds simple, but plenty of people fail at even this basic level of civility. This isn't to say you can't say that a project didn't work for you or you disagree with something, but there's a massive difference between saying "I tried the project and it didn't meet my needs" and "this project is trash".
People failing to support this basic level of civility is what leads to burnout.
Be an advocate
It's rather indirect, but saying nice things about a project is a way of showing thanks. As an example, I have seen various people talk positively about
pyproject.toml
online, but not directly at me. That still feels nice due to how much effort I put into helping make that file exist and creating the
[project]
table
.
Or put another way, you never know who is reading your public communications.
Produce your own open source
Another indirect way to show thanks is by sharing your own open source code. By maintaining your own code, you'll increase the likelihood I myself will become a user of your project. That then becomes a circuitous cycle of open source support between us.
Say thanks
Directly saying "thank you" actually goes a really long way. It takes
a lot
of positive interactions to counteract a single negative interaction. You might be surprised how much it might brighten someone's day when someone takes the time and effort to
reach out
and say "thank you", whether that's by DM, email, in-person at a conference, etc.
Fiscal support
As I said in the opening of this post, I set up
GitHub Sponsors for myself
as a way for people to show fiscal support for my open source work if that's how they prefer to express their thanks (including businesses). Now I'm purposefully not saying "sponsor" as to me that implies that giving money leads to some benefit (e.g. getting a shout-out somewhere) which is
totally reasonable
for people to do. But for me, since
every commit is a gift
, I'm financially secure, and I'm not trying to make a living from my volunteer open source work or put in the effort to make sponsorship worth it, I have chosen to treat fiscal support as a way of showing reciprocity for the gift of sharing my code that you've already received. This means I fully support all open source maintainers setting up fiscal support at a minimum, and if they want to put in the effort to go the sponsorship route then they definitely should.
Producing open source also isn't financially free. For instance, I pay for:
My personal time away from my wife and child, family and friends (which my
open source journal
exists to try and point out for those who don't realize how much time I put into my volunteer work)
So while open source is "free" for you as the consumer, the producer very likely has concrete financial costs in producing that open source on top of the intangible costs like volunteering their personal time.
But as I listed earlier, there are plenty of other ways to show thanks without having to spend money that can be equally valuable to a maintainer.
I also specifically didn't mention contributing. I have said before that contributions are like giving someone a puppy: it seems like a lovely gift at the time, but the recipient is now being "gifted" daily walks involving scooping 💩 and vet bills. As such, contributions from others can be a blessing and a curse all at the same time depending on the contribution itself, the attitude of the person making the contribution, etc. So I wouldn't always assume my contribution is as welcomed and desired as much as a "thank you" note.
The biggest update since June 2023 is WASI is now a tier 2 platform for CPython! This means that the main branch of CPython should never be broken more than 24 hours for WASI and that a release will be blocked if WASI support is broken. This only applies to
Content Preview
The biggest update since
June 2023
is WASI is now a
tier 2 platform for CPython
! This means that the
main
branch of CPython should never be broken more than 24 hours for WASI and that a release will be blocked if WASI support is broken. This only applies to Python 3.13 and later, although I have been trying to keep Python 3.11 and 3.12 working with WASI as well.
Starting in
wasmtime 14
, a new command line interface was introduced. All the relevant bits of code that call wasmtime have been updated to use the new CLI in Python 3.11, 3.12, and 3.13/
main
.
At this point I think CPython has caught up to what's available in WASI 0.2 and
wasi-libc
via WASI SDK. The
open issues
are mostly feature requests or checking if assumptions related to what's supported still hold.
I'm on parental leave at this point, so future WASI work from me is on hold until I return to work in June. Another side effect of me becoming a parent soon is I stepped down as the sponsor of
Emscripten
support in CPython. That means CPython 3.13 does not officially support Emscripten and probably starting in 3.14, I will be removing any code that complicates supporting WASI. The
Pyodide project
already knows about this and they don't expect it to be a major hindrance for them since they are already used to patching CPython source code.
An experimental pip subcommand for the Python Launcher for Unix
There are a couple of things I always want to be true when I install Python packages for a project:I have a virtual environmentPip is up-to-dateFor virtual environments, you would like them to be created as fast as possible and (usually) with the newest version
Content Preview
There are a couple of things I always want to be true when I install Python packages for a project:
I have a virtual environment
Pip is up-to-date
For virtual environments, you would like them to be created as fast as possible and (usually) with the newest version of Python. For keeping pip up-to-date, it would be nice to not have to do that for every single virtual environment you have.
To help make all of this true for myself, I created an experimental
Python Launcher for Unix
"subcommand":
py-pip
. The CLI app does the following:
Makes sure there is a globally cached copy of pip, and updates it if necessary
Uses the Python Launcher for Unix to create a virtual environment where it finds a
pyproject.toml
file
Runs pip using the virtual environment's interpreter
This is all done via a
py-pip.pyz
file (which you can rename to just
py-pip
if you want). The
py-pip.pyz
file available from a
release of py-pip
can be made executable (e.g.
chmod a+x py-pip.pyz
). The shebang of the file is already
set to
#!/usr/bin/env py
so it's ready to use the newest version of Python you have installed. Stick that on your
PATH
and you can then use that instead of
py -m pip
to run pip itself.
To keep pip up-to-date, the easiest way to do that is to have only a single copy of pip to worry about. Thanks to the pip team releasing a self-contained
pip.pyz
along with pip always working with supported, it means if we just cache a copy of
pip.pyz
and keep that up-to-date then we can have that one copy to worry about.
Having a single copy of pip also means we don't need to install pip for each virtual environment. That lets us use
microvenv
and skip the overhead of installing pip in each virtual environment.
Now, this is an experiment. Much like the Python Launcher for Unix, py-pip is somewhat optimized for my own workflow. I am also keeping an eye on
PEP 723
and
PEP 735
as a way to only install packages that have been written down somewhere instead of ever installing a package à la carte as I think that's a better practice to follow and might actually trump all of this. But since I have seen others have frustration from both forgetting the virtual environment and having to keep pip up-to-date, I decided to open source the code.