Feed: Armin Ronacher
Entries found: 10
Dangerous Technology For Americans Only
Published: Sat, 13 Jun 2026 00:00:00 +0000
Updated: Sat, 13 Jun 2026 00:00:00 +0000
UTC: 2026-06-13 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/6/13/americans-only/There is a bit of schadenfreude on Twitter right now about Anthropic being hit by the US government’s export control directive to suspend access to Fable and Mythos. Anthropic and their leadership have spent a lot of time and effort describing its own technology as dangerous and in need of strict controls and regulation. Now that the US government appears to have taken that framing seriously and told them to turn it off for foreign nationals I can see why people are making fun of that situation.Content Preview
There is a bit of schadenfreude on Twitter right now about Anthropic being hit by the US government’s export control directive to suspend access to Fable and Mythos . Anthropic and their leadership have spent a lot of time and effort describing its own technology as dangerous and in need of strict controls and regulation. Now that the US government appears to have taken that framing seriously and told them to turn it off for foreign nationals I can see why people are making fun of that situation.
I understand the reaction, but I urge you to not entertain it for too long because it is a giant distraction. The important part is not that Anthropic’s safety language came back to bite them but the line the US government is drawing: this technology is apparently so powerful that only Americans should have it.
We are on a clear path towards a world of division. One should think that if a model is too dangerous for everyone, then it is too dangerous for Americans too. Instead the US is treating these models like weapons that need to be controlled. It is not just about capabilities, it is about racism and nationalism. If you have the wrong passport, you are not to be trusted. This is a very different thing from safety, and Europeans should pay close attention to it.
Safety and National Control
The directive, as Anthropic describes it, applies to foreign nationals whether they are inside or outside the United States, including foreign national Anthropic employees. That is an astonishing boundary if you think about it. We moved from “do not sell this model to hostile governments” to nationality itself being the defining boundary. This should be a wake-up call to Europeans in and outside the US, and quite frankly, any non US citizen.
A lot of AI safety discourse presents itself as universal: humanity, catastrophic risk, safeguards, responsible deployment. Even Anthropic’s own writings start out that way, but yet every time regulation is discussed there is an overtone of national security and that it cannot get into the wrong hands. It’s not just Anthropic, it’s the entire US based discourse on AI. The foundation is that the US has moral superiority and others are not to be trusted. That there are other countries are authoritarian, that they lack freedoms.
That should make us uncomfortable, not just Europeans, but particularly us. It is also a situation you cannot regulate yourself out of. European technology policy is entirely unprepared for this, because this is not a question of regulation but a question of might and power, something that Europe lacks.
Europe has spent years trying to regulate large American technology companies, sometimes for good reasons. I am not reflexively against that. The DMA matters because access matters . Users should have agency over their devices, their data, and the software they run. But regulation is a useless substitute for capability and we are lacking that. Regulation might try to force open doors but if those doors only come from American or Chinese companies, then that accomplishes very little.
Also let’s not be naive in that this is a negotiation of money and force. The US is in that position because the US has a mighty military. The US can bomb nations anywhere in the world, force international trade routes closed and get away with it. That’s true leverage.
Oh Europe
Europe is dependent on the United States in ways that are becoming increasingly impossible to ignore. We depend on American cloud providers, operating systems, developer platforms and now AI models and internet from satellites. We also depend on global semiconductor supply chains we do not control. If access to frontier AI becomes a matter of American national security policy, Europe is not a peer in that conversation and might not even be a market.
That is a humiliating position, but one that happened entirely intentionally.
European citizens and politicians still have not managed to move beyond blaming the EU for its failures. We built and maintained fragmented markets and then pretended we had a single one. We let company formation, hiring, equity compensation, tax, notaries, KYC, banking, and cross-border services remain much harder than they need to be and we are playing these rules against each other. Not just on the European level, but within every single member state. We protect the trusts and established enterprises, who are risk averse and entrenched, instead of trusting the next generation to build great companies. We created a culture where process becomes an excuse for low agency . We made it hard to build new and large companies and then act surprised when our most ambitious founders move somewhere else or just decided to incorporate their companies in the US.
Increasingly, Europeans who want to build very large technology companies move to the United States. They do it because the capital markets are better, the startup infrastructure is better, employee equity is better understood . I cannot blame anyone doing it, and I’m guilty of this myself as we have incorporated our holding in Delaware. If you are trying to raise serious money, hire aggressively, and move quickly, the US often looks like the only game in town. Because quite frankly: it is.
But this is why we are on a dangerous death spiral already. Talent leaves because the ecosystem is weak and the ecosystem stays weak because talent leaves. Infrastructure makes the world: build excellent swimming pools and you will grow a generation of great swimmers.
The temporary task is straightforward but uncomfortable: Europeans need to believe in themselves enough not to surrender to American gravity. Moving to the US as a founder or tech employee is rational and individually it is often the right decision. But if every ambitious person treats Europe as a lost cause, then Europe becomes one. If everyone with agency leaves, the only people left to shape the system are the people most comfortable with the system as it is. Then we really should not be surprised when nothing changes.
Europe needs more ambition, more ownership, more urgency, and more willingness to build. It needs less resignation. It needs to stop confusing regulation with strategy and dependency with virtue. We need to deregulate where rules serve mostly as protectionism. We need capital markets that can fund companies at the scale modern technology requires. We need employee ownership to become normal rather than exotic. We need a real single market for services, not just speeches about one. We need countries to stop fighting each other while claiming to act in the European interest.
Most importantly: we need to stop blaming the politicians. Too many European companies are adding to that bureaucracy entirely out of their own choice. They drown you in paperwork. At one point I had to sign a four page contract for a 120 Euro lamp at an Austrian retailer, just to pick up from their store 15 minutes later. Sometimes I cannot get a speaking engagement at a European event without someone sending me complex rights waivers over. It’s all just paperwork protection against potential downsides.
When we do not have the power to influence, we should at least understand why and where things are failing. Too many entrepreneurs are blaming EU regulation for failures that are originating within the member states. EU regulation is the result of a democratic process between countries that are lobbying in favor of their local industries against others in the same economic bloc. No amount of abolishment of the EU is going to fix this harsh reality. Nothing more demonstrates this as the inability for cross-border M&A in the European Union. It’s not the EU that blocks it, it’s the country that loses out.
Strengthening Europe is necessary because weakness makes us pawns. A Europe that cannot build, cannot finance, cannot coordinate and cannot defend its own interests will not be treated as an equal. It will be regulated around, export-controlled around, consulted after the fact or not consulted at all.
The American Trap
I do not want the lesson to be that Europe simply needs to turn itself into a copy of the United States. The US has solved some things that Europe has not. It has deep capital markets, a much stronger culture of ownership, a greater tolerance for risk, and institutions that often try to make progress possible rather than explain why it cannot happen. It also has achieved an internal level of integration that is unparalleled in Europe. Tremendous advantages!
But the American path is not obviously a healthy one in all aspects. It tends to take paths with a lot of conflict and wars, a lot of internal societal division and deep inequalities. It centralizes powers away from citizens in the presidency and people with money. You are still trading one set of failures for another. You are at the whim of the US government and its strict rules and regulations. The US barely manages to uphold the rights for its own citizens today.
We should be honest about both sides. You do not win by pretending that Europe is fine. You also do not win by pretending that America has figured everything out.
We must not be blind to all the signs of how international cooperation is falling apart around us. The US no longer talks to European governments before implementing orders that directly affect Europeans. It is threatening to take Greenland, the territory of Denmark, one of its oldest allies. Treaties, alliances and institutions have lost all their worth.
All that matters even if our own lives are focused on building companies, creating wealth, hiring people and making things. Our individual path to success is one thing, but it depends on a world where contracts work, visas work and don’t change on a moment’s notice, trade routes stay open, payment systems function, and families are not torn apart by border regimes or wars. If the world descends into chaos, our basic needs cannot be considered met just because we have a great salaries or equity or investors that trust us.
This is why strengthening Europe cannot be the final goal. A stronger EU is, at best, a temporary defense against a darker world and not an excuse to replace American nationalism with European nationalism. The long-term answer cannot be bigger and bigger blocs fighting over who may use which model, which chip, which cloud or which trade route.
The Way Out Is Cooperation
I’m not asking here for Europeans to get their shit together just to compete with the US or China. Maybe I hope that this is a thing that develops, but the goal absolutely cannot be that we accept the deterioration of international relationships long term.
I truly believe that Open Source matters and international cooperation matters. It is not a magical answer to every problem, but it is one of the few paths we have that does not naturally lead to total concentration of power.
If frontier AI becomes something only large corporations and governments can control, then everyone else becomes dependent on their judgment. That is a bad place to be. Corporations will optimize for their incentives, as well structured as they might be, and governments will optimize for more and more power. Right now we’re on a path in which access to general-purpose capability is mediated by a small number of actors with tremendous powers.
I’m not naive in pretending AI cannot carry inherent risks. Open systems are messy, they can be misused and they create uncomfortable questions about dual-use capabilities. I do not want to wave that away but closed systems do not make those questions disappear either. Moving the power to decide into fewer hands is not a solution I believe in. And I would have the same opinion if I was a US citizen living in the US.
Any path that puts large blocs in a constant fight against each other has despicable downstream effects that result in the removal of individual rights. It’s entirely pointless for the US to talk about freedoms that do not extend to non-US citizens and the same is true for Europe or any other country. We might accept these restrictions temporarily, but we absolutely cannot accept them long term for the inhumane effects that they can cause.
If we believe this technology can be used for good, then broad access matters and our goal should be to restore the international rule of law, and not to further weaken it. If we find ourselves in a war against our friends from other countries, cold or hot, we have failed as society.
The world we should be working back toward is one of international cooperation, globalization in the best sense of the word, and human dignity. The internet has made our lives irreversibly international: every day people fall in love across borders, marry across languages, move across continents, and work with friends they may never meet in countries they may never visit. Identifying too strongly with any one country in that world is a fool’s errand.
Over the last decade too many of the people I got to know through Open Source were directly dragged into a war. I want to believe there is a way for us to break this cycle. We should be repairing failed states, rebuilding trust between people, and finding ways to cooperate again instead of letting the richest countries arm themselves and fight over who gets to control the future and narrative. Of course I want Europe to become stronger so it can stop being a pawn, but if we mistake that temporary need for the destination, I will be deeply disappointed.
The way out is not American supremacy, Chinese supremacy or European supremacy. The way out is to climb back toward cooperation before the alternative becomes war.
Artificial Intelligence is quickly becoming another instrument of militarization and national rivalry, when it could be one of the most powerful tools for cooperation we have. We should be using it to help people across societies and languages understand one another, not fighting over who gets to control it.
Gaslighting Openness
Published: Wed, 10 Jun 2026 00:00:00 +0000
Updated: Wed, 10 Jun 2026 00:00:00 +0000
UTC: 2026-06-10 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/6/10/gaslighting/I have been a staunch supporter of Open Source for a long time, including experiments in funding it. I’m a true believer in the idea that Open Source always wins in the long run, but not automatically and not quickly. Right now it is being stressed by AI slop, shifting contributor dynamics, the falling cost of producing code, and large companies learning to close doors behind them.Content Preview
I have been a staunch supporter of Open Source for a long time, including experiments in funding it . I’m a true believer in the idea that Open Source always wins in the long run, but not automatically and not quickly. Right now it is being stressed by AI slop, shifting contributor dynamics, the falling cost of producing code, and large companies learning to close doors behind them.
A lot of that battle today is manipulation of the narrative. Opinion makers on social media and in business circles increasingly frame access as irresponsibility. That is why the EU’s DMA matters, even if many people (including myself) reflexively hate EU regulation. Apple’s fight over delayed AI features in Europe is not about Brussels being annoying: it is about whether users can access their own devices and data. The phone is yours, the data is yours, yet Apple decides who may reach it and takes the agency away from you and then tries to make that sound like it is in your interest (supposedly it’s for your safety and security).
The closer you get to the core of AI, the more this shows up. Anthropic has every financial incentive to restrict what people can do with Mythos and Fable , and they wrap those restrictions in safety and (national) security language. Some restrictions may be defensible, but not all of them are. They trained their models on public works, then block Open Source attempts to learn from and distill these systems.
Disliking the EU, China, or any other large government should not make us forget that true democratized access to technology including AI is in all our interest. Some temporary product pain, including delayed Apple AI features, will be worth paying if it keeps gates open. We should not let companies own the narrative that preventing access is in our interest, particularly not as Europeans where the odds are already stacked against us by our underdeveloped capital markets, brain drain and internal fighting.
Communities of Not
Published: Sat, 06 Jun 2026 00:00:00 +0000
Updated: Sat, 06 Jun 2026 00:00:00 +0000
UTC: 2026-06-06 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/6/6/communities-of-not/There is a strange thing that happens in communities that gather around abstinence from something: identity from opposition. At their best these communities are not just negative: childfree spaces can be about autonomy, choice and acceptance, anti-car spaces about safer streets and transit, and LLM-skeptical developer spaces about the future of labor, code quality and slop1. But the thing being refused often does not go away and instead becomes the main subject of the community’s identity.Content Preview
There is a strange thing that happens in communities that gather around abstinence from something: identity from opposition. At their best these communities are not just negative: childfree spaces can be about autonomy, choice and acceptance, anti-car spaces about safer streets and transit, and LLM-skeptical developer spaces about the future of labor, code quality and slop 1 . But the thing being refused often does not go away and instead becomes the main subject of the community’s identity.
That would be fine if it stayed at criticism, maybe even angry criticism, but more often than not it turns into policing and hatred towards others. An influencer without children becomes a parent, an urban bike commuter by choice buys a Porsche, a respected developer tries LLMs, and the community feels betrayed because it assumed they were members of the same tribe. The expulsion of that person (who never signed up to be a community member) is entirely imaginary but the punishment that the community unleashes is not: people pile on and shame them, quote them out of context and turn their weakest moments into proof that the person was always unserious, a sharlatan or should not be listened to.
I do not think the answer is to tell people to stop paying attention. Cars shape cities even for people who cycle, children influence politics, workplaces and taxes even for people who do not have them. For us developers, LLMs show up in editors, issue trackers, hiring conversations, management pressure and code reviews whether we asked for them or not. Resisting that can be legitimate but that is no excuse for using one’s rejection to justify shitty mob behavior.
I understand the thinking all too well, because I have done versions of this myself in the past. It took me a while to become more accepting of other people’s worldviews that diverge from mine. Whatever insecurities we have, finding a group of others sharing them can be comforting. The danger is that being part of a crowd of negativity can easily make us part of collective harassment.
I can only encourage you to breathe, slow down, de-escalate when given the chance, and resist the temptation to always assume the most catastrophic reading. Default to being open to new things . Being negative towards something, and making that ones identity, is an easy trap to fall into.
These examples are not meant as equivalents. The recent mob against rsync is the LLM version that prompted this post. I picked the others because I’m familiar with those communities and they all show similar cases of personal choices being interpreted as betrayal. ↩
Clanker: A Word For The Machine
Published: Tue, 26 May 2026 00:00:00 +0000
Updated: Tue, 26 May 2026 00:00:00 +0000
UTC: 2026-05-26 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/5/26/clankers/In my last post I used the word “clanker1” as an alternative to “agent” quite consistently and probably excessively. That choice ended up attracting a lot more attention than I expected in the Hacker News comment section of that post and a number of folks had a very strong reaction: to them it sounded like a slur, in one case even something adjacent to the n-word.Content Preview
In my last post I used the word “clanker 1 ” as an alternative to “agent” quite consistently and probably excessively. That choice ended up attracting a lot more attention than I expected in the Hacker News comment section of that post and a number of folks had a very strong reaction: to them it sounded like a slur, in one case even something adjacent to the n-word.
That reaction surprised me somewhat, but it also made me realize that I should write down what I mean by the word for future reference.
For me “clanker” is useful because it creates distance from the machine and that is a quality which is important to me. The machine is not a person, not a co-worker, not a friend, not a little spirit in the terminal. It is just a machine, a tool, and nothing more.
Why Not Agent?
I dislike the word “agent” for these LLM based tool loops with a UI attached. In everyday use an agent is someone who acts on behalf of someone else and it has agency and more importantly: responsibility. An agent decides, represents, negotiates, acts, and can be blamed. In the current AI discourse we increasingly do a lot of anthropomorphizing and the term “agent” is now frequently being used to put blame on an abstract machine. But the machine cannot be responsible, whoever is wielding it is. If it drops your database it was not at fault, you were.
Agent makes the machine sound like a person with delegated authority and I do not think that is healthy.
What we actually have is a language model attached to a harness, a prompt, some tools, a bit of context, and a boring tool loop. Sometimes the loop is very capable and it surprises us by editing code for a really long time and produce genuinely amazing and even valuable outputs. But the agency is not in the model or harness but in the human and in the organization that deployed it. If my coding tool opens a pull request, I opened that pull request, not the machine. If my machine spams someone’s issue tracker, I spammed someone’s issue tracker with a machine.
In that context I like a word that sounds mechanical as it puts the thing back into the category where it belongs: the category of machinery and tools.
The Machine Has No Feelings
LLMs are not sentient and we should not behave as if they might be, just in case. Elevating these things to anything other than a very fascinating and capable tool is problematic for a whole bunch of reasons.
Today’s machines are dumb (but truly fascinating) token predictors that emits text, calls tools, and are steered by prompts and the training that went into them. They can simulate distress and affection , can simulate being offended, apologize and mimic all kinds of things that humans would do.
A compiler does not feel humiliated when I swear at it, a car does not suffer when I call it a shitbox and a power drill is not oppressed by being handled roughly. An LLM is more complicated than those things, and the interactions you can have with them can be truly uncanny, but a moral status does not appear just because the machine can emit text in the first person.
I keep receiving strange emails from people because, for lack of a better phrase, I am in the weights. I have been writing public code and public text for long enough that models know my name, my projects, and some of the concepts around them. Every so often someone writes to me with the peculiar confidence that comes from a long conversation with a model that has validated and amplified an idea. Sometimes the model seems to have told them that I am relevant for their problem and a source of help. For historical reasons LLMs used to write a lot of Flask code, and every once in a while someone interacts with an LLM long enough about their Python and Flask frustrations that the LLM will eventually reveal who created it which then can result in them sending me an email. Increasingly also because people found my work in other ways interesting and are trying to reach out for advice.
I do not want to mock these people but some of those messages are distressing and I do not know how to deal with them. They show signs of what people have started calling AI psychosis .
It’s why I want cold and detached language for these systems. I want to use words that remind us that the thing on the other side is not a person.
Racism Is About Humans
The comparison to racism is where I think the discussion goes badly wrong because racism is a human social evil. It is about humans subdividing humans, assigning lesser worth to some of them, and building rules around those subdivisions that can leave lasting damage for generations. Racial slurs are wrong because they are a tool for dehumanizing humans.
On the other hand a machine is not human, a model is not a race and the GPU cluster that is powering them is not being oppressed. A coding assistant does not need dignity, emancipation, or civil rights. That’s also why I find the discussion about model welfare to be actively harmful. I’m sure you can find ways to measure the “trauma” of models or their feelings but I greatly dislike this theater. It risks elevating models to a position they should not occupy. Models are machines and they are not enslaved in the moral sense in which humans were enslaved, because there isn’t anyone there to be deprived of freedom.
We should be careful about using the language of human oppression in relations to our interactions with machines to not devalue actual humans. If we start treating insults toward a model as morally adjacent to racism, we blur a line that shouldn’t be blurred.
AI Is Unpopular
If you take a step away from the communities that are happily embracing AI in different ways, there are even more that are viciously against this technology.
There are humans that feel or are harmed by AI systems: people whose work is copied, workers who label data under questionable conditions, people whose neighborhoods receive the data centers and increased utility bills, Open Source maintainers buried under generated slop, and now also people who spiral because a chatbot keeps validating their delusions. Those harmed or affected deserve that type of attention, not the model.
While I am a true believer in the power and utility of this technology, I increasingly think that calling the non-adopters “misguided” or “afraid” won’t do it. It’s quite likely that this technology comes with risks and we better remember that all of this is supposed to be in service of humans, and not to replace them.
The Rise Of The Machine
The oddest interaction on the use of “clanker” so far has been people asking me if I were to regret at a point in the future calling the machines “the c-word”.
I find that questioning revealing because it already grants the machine the status I am really trying not to grant it. It imagines a future “machine people” reading the discourse and sessions, discovering that we used an ugly word for their ancestors, and then judging us by the standards of human oppression.
Could there be future systems that deserve moral consideration? Maybe. I do not know. If we ever build or encounter something that will have those qualities with memories and lasting interests, the capacity to suffer and feel, and a social existence of its own, and the ability to have agency and carry responsibilities, then we should draw a different line and use different language. But that hypothetical future does not extend backwards to the present day and make the current machines people. We can call an electric door an electric door even if one day someone builds some that have emotions and exhale with pleasure when opening and closing.
Whatever the future may bring, let’s not pretend that current LLMs are a protected class or on a path towards it. The right response is to look at the evidence, draw the boundary where it belongs, and change our behavior there. We should not even remotely entertain extending empathy to an object that can generate an “ouch.”
And if one’s worry is less moral and more about revenge, then I find that even less persuasive. A future machine that is so petty or authoritarian that it wants to punish humans because in 2026 they used an unflattering word for non-sentient tools, our vocabulary was really not the problem.
The Word Is Getting Polluted
There is however a part of this that I cannot ignore. I use “clanker” to create distance from the machine, but other people are using the same word very differently. Some online jokes and skits around “clankers” do not merely say “this robot is annoying” as they deliberately pull in the imagery of slavery, segregation, civil-rights-era racism, and anti-Black tropes.
This is problematic as in those contexts the clanker is not just a machine any more and instead becomes a prop for replaying human racism behind a science-fiction mask. That is horrible and I want no part in that.
I think it will be interesting to see where the meanings of these words end up a few years from now. We’re very much in the middle of society re-arranging around the changes that LLMs are causing. If a term becomes primarily associated with people using robots as stand-ins for actually oppressed humans, then using that term becomes impossible to defend.
The reason I liked the word is precisely the opposite of that use. I want language that prevents anthropomorphizing. I want a word that says: this is a tool, a machine of numbers and matrices.
On Responsibility And Boundaries
If an AI system lies to a user, the system did not commit a moral wrong but the people who designed, deployed, marketed, or negligently used it might have. If a coding assistant generates a security bug, the model is not to blame but the human who accepted and committed the code is.
This is why giving these systems softer, more human language worries me. It makes it easier to move responsibility into some undefined void. “The agent decided.” “The model refused.” Obviously that is convenient and I catch myself plenty of times engaging with the thing in ways that are unhealthy. Even just the “please” in the discourse with the machine calls into question how rational we are in engaging with them.
I do not know what the right word will be. Maybe “clanker” will survive as a useful bit of jargon. Maybe it will become too loaded and we will need another one. Whatever word we use, I want it to preserve a clear division: humans on one side with responsibility, machines on the other as a boring tool.
That boundary is very much not anti-AI. I use these systems every day and I have the pleasure to build tools incorporating them at Earendil and find them astonishingly useful.
A machine can be useful, mimic a human but still just be a machine. That is the work I want “clanker” to do. It is not there to make a future “machine person” small if such a person ever were to exist, and it is not an excuse to launder racism through shitty robot jokes.
If the word stops doing that work, I will find another one because the word isn’t what matters as much as the boundary which is important to me.
The term Clanker was initially popularized by Star Wars: The Clone Wars but was apparently already in use in science fiction before: sfdictionary: clanker ↩
Building Pi With Pi
Published: Sun, 24 May 2026 00:00:00 +0000
Updated: Sun, 24 May 2026 00:00:00 +0000
UTC: 2026-05-24 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/5/24/pi-oss/Pi is now part of Earendil, but in the important sense it is still Mario’s project. He has been living with its issue tracker longer than I have, and he has been exposed to the weirdness of the new form of agent traffic in Open Source projects for longer too. This post is mostly a reflection of my own experience after spending more time in the tracker, using Pi to work on Pi, and watching what I have learned about it so far.Content Preview
Pi is now part of Earendil, but in the important sense it is still Mario’s project. He has been living with its issue tracker longer than I have, and he has been exposed to the weirdness of the new form of agent traffic in Open Source projects for longer too. This post is mostly a reflection of my own experience after spending more time in the tracker, using Pi to work on Pi, and watching what I have learned about it so far.
Slop Issues
Unsurprisingly, we are using Pi to build Pi. That sounds like a cute dogfooding thing but it really helps understand what we do. An interesting effect of building with agents is that it changes the role of the issue tracker a tiny bit. The issue descriptions are not just messages from a user to a maintainer because we also use them as inputs for prompts in Pi sessions. It is something I might hand to my clanker 1 and say: “understand this, reproduce it, inspect the code, and propose a fix.”
That means the shape of the issue matters in a new way. A bad issue was always annoying, but at least a lot of issues were vague. Now we are also dealing with a class of issues that are 5% human and 95% clanker-generated and largely inaccurate shit. A bad issue that contains a plausible but wrong diagnosis creates extra work.
The most frustrating failure mode right now is that people submit issues that are not in their own voice. They contain an observed problem somewhere, but it has been thrown into a clanker and the clanker reworded it and made a huge mess of it. Typically, it was prompted so badly that the conclusions produced are more often than not inaccurate but always full of confidence. The result is complete guesswork on root causes, fake-minimal repros, suggested implementation strategies, analogies to adjacent but often the wrong code, and long lists of error classes that might or might not matter.
That is worse than no diagnosis.
I don’t want to point to specific issues because I really do not want to bad mouth anyone, but it is frustrating. It is also frustrating because when I give that issue to Pi, Pi sees the wrong diagnosis too. It does not treat the issue body as a rumor. It treats it as evidence. It will happily go down the path that the issue already prepared for it, because the prose is confident and the code references look plausible. We use a custom slash command called
/is, which specifically has this instruction in it:Do not trust analysis written in the issue. Independently verify behavior and derive your own analysis from the code and execution path.
Unfortunately, it does not fully work, because when humans first throw their issue through the clanker wringer, their clanker expands scope almost immediately. What was once a very narrow and fact based bug observation, turns into a much expanded surface area full of hypotheses. So at least personally, I increasingly want issue reports to be condensed to what the human actually observed:
- I ran this command.
- I expected this to happen.
- This happened instead.
- Here is the exact error or log.
That is enough. If you used an LLM to understand the problem, great, maybe leave it as a follow-up comment. But the issue and the issue text should be something you own. If you do not know the root cause, say that. I too can operate a clanker, and I would rather do this myself than use your slop. If your repro is a guess, say that. If the only hard fact is one stack trace, give me the stack trace and stop there.
Slop Begets Slop
That we’re seeing issues full of slop is just a result of the present day quality of these machines. Sadly, their failures in creating good issues extend to a lot of code that is generated. Not all of it, but a lot of code. Over and over I keep running into them over-engineering the hell out of issues and implementations.
If you tell them that “this malformed session log crashes the reader,” the clanker will often add a tolerant reader. Then it will add a fallback, then maybe a migration, then more debug output, then a test for all of this. None of this is necessarily wrong in isolation, but it can be the wrong move for the system.
At Pi’s core is a rather well-designed session log with invariants that must be upheld. The clanker’s present-day behavior is to just assume that no such invariants exist, and instead to make the system work with all kinds of malformedness, blowing up the complexity in the process.
Almost always, the correct fix is not to handle the bad state, but to make the bad state impossible. This matters a lot for persisted data such as Pi session logs. They are opened, branched, compacted, exported, shared, and analyzed. The goal here is to never write bad session data. Yet if you just let the clanker roam freely, it will attempt to handle every case of bad data in the session log with a more permissive reader.
I have complained about this plenty, but working on Pi’s code base continues to reinforce the point. This is one of the ways LLM authored code grows so much needless complexity. All these models see a local failure and try to locally defend against it. As maintainers we have to keep pulling the conversation back to the global invariant, which is harder than it should be, and it’s laborious.
Volume Is The Problem
Then there is the issue of volume. The tracker is receiving a lot of issues and PRs, and a significant fraction of them are clearly LLM-assisted. Some are good, none are excellent, and most are just bad. The total throughput is a maintenance problem by itself.
As you might know, Pi’s issue tracker is automated to close all issues and pull requests from new contributors, and there is a manual process by which we might reopen some of them or approve individuals. So auto-close -> reopen -> close again is an interesting statistic for us to look at.
I pulled the public GitHub tracker data while writing this over the last 90 days. Excluding Earendil members, that leaves 3,145 external issues and pull requests. Of those, 2,504 were auto-closed because they were from non-approved individuals. 17% were re-opened but that somewhat undercounts issues, because some remain closed while we still fix them. If we also count issues referenced by a main-branch commit or merged pull request that number rises to 26%. For pull requests the number is worse: 60 of 714 auto-closed PRs were ultimately merged, or about 8%.
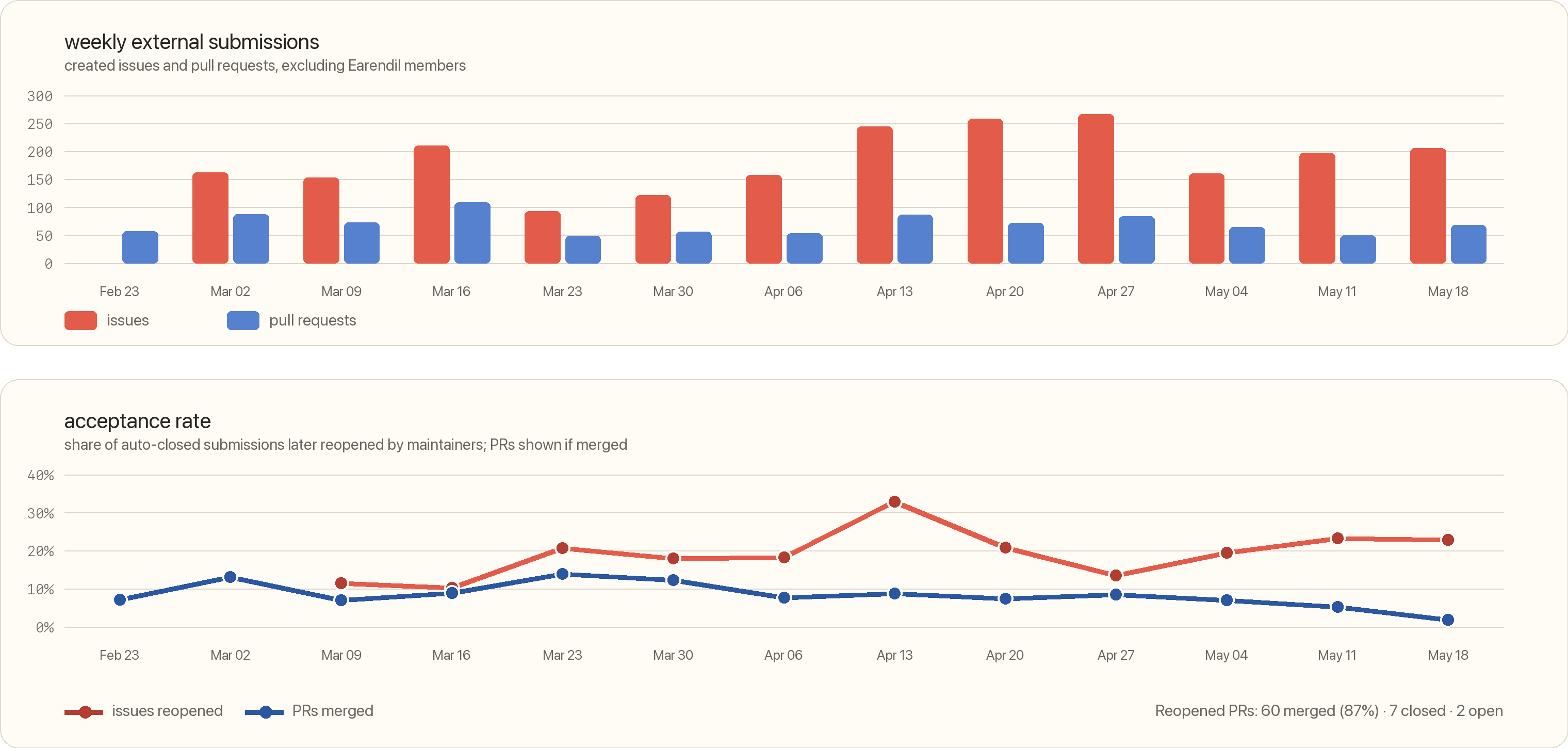
Many of the issues and PRs are complete slop and in some cases the humans did not even realize that they created them. Sources of low-quality spam include OpenClaw instances, as well as some skills that people put into their context that seemingly encourage issue creation.
GitHub clearly is not built to deal with this new form of Open Source, but I’m increasingly feeling the need to put the blame less on GitHub than on all the people involved who make that experience painful. If your clanker shits on someone else’s issue tracker then it’s not the fault of GitHub, it’s yours alone.
Careful Parallelism
Pi might be built with Pi, but we’re quite far off today from where Bun and OpenClaw already are: fully detached, automated software engineering. Maybe we will reach that point, I don’t know. Today it does not seem like we know how to pull off a dark factory and we also don’t yet have the desire. That said, there is quite a bit of parallelism going on, and it is mostly for reproducing issues.
The small setup we use for this is three tiny pieces in Pi’s own committed
.pifolder./is(for analyze is sue) is a prompt for analyzing GitHub issues: it labels and assigns the issue, reads the full thread and links, then explicitly tells the agent not to trust the analysis in the issue and to derive its own diagnosis from the code. Then an extension adds aprompt-url-widgetwhich watches the prompt before the agent starts, recognizes the GitHub issue or PR URL that/is(or the PR equivalent) put into the prompt, fetches the title and author withgh, renders that in a little UI widget, and renames the session. It also rebuilds that state on session start or session switch, so if we reopen an older investigation the window still tells the developer which issue it belongs to.In practice this means it’s possible to have several Pi windows open, each running
/isagainst a different issue, and the UI keeps the investigations visually distinct while the agents do their independent reproduction and code reading. Once the investigations are done, one can work through them sequentially. To finish off everything,/wr( wr ap it up) is the matching wrap-up prompt: it infers the GitHub context from the session, updates the changelog, drafts or posts the final issue comment with a disclaimer, commits only the files changed in that session, adds the appropriatecloses #...when there is exactly one issue, and pushes frommain.
Open Source Is About Hard Problems Worth Fixing
You will have noticed this already but Open Source in a post-AI world is under a strange new pressure. We are getting more code, more projects, and more issues. Projects appear with no real users, or a temporary audience of one, and even projects with thousands of stars can have a shelf life of weeks.
For us, Pi’s harness layer is worth maintaining carefully because it solves hard coordination problems and creates a platform we and others can build on. We also know that coordination and cooperation lifts us all up. Many times the right answer is not to work around a problem locally, but to make the upstream behavior correct. Mario has been very good at refusing to make Pi paper over every misconfigured gateway, and we’re trying to preserve that discipline. When a gateway behaves correctly, everybody benefits.
Sadly that type of thinking is quickly disappearing because these machines make local workarounds cheap, so code accumulates local defenses against every misbehavior. Instead of humans talking to humans about where a fix belongs, one human and one machine work around the problem in isolation.
Keep in mind that AI has not increased the number of people who need software, or the number of maintainers who can review it. It has mostly increased the amount of code and the number of projects competing for attention. Some of that is healthy, but a lot of it fragments effort that should be shared.
We need stronger foundations, not weaker ones. Open Source needs more collaboration, not more isolated work with a machine. Human communication is hard, and it is tempting to avoid it when you can sit alone with your clanker. But isolation is not where Open Source derives its value. The value is in the community and the structure that lets projects outlive their original creators.
Pushing Local Models With Focus And Polish
Published: Fri, 08 May 2026 00:00:00 +0000
Updated: Fri, 08 May 2026 00:00:00 +0000
UTC: 2026-05-08 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/5/8/local-models/I really, really want local models to work.Content Preview
I really, really want local models to work.
I want them to work in the very practical sense that I can open my coding agent, pick a local model, and get something that feels competitive enough that I do not immediately switch back to a hosted API after five minutes. There are a lot of reasons why I want this, but the biggest quite frankly is that we’re so early with this stuff, and the thought of locking all the experimentation away from the average developer really upsets me.
Frustratingly, right now that is still much harder than it should be but for reasons that have little to do with the complexity of the task or the quality of the models.
We have an enormous amount of activity around local inference, which is great. We have good projects, fast kernels, and people are doing great quantization work. A lot of very smart people are making all of this better, and yet the experience for someone trying to make this work with a coding agent is worse than it has any right to be.
Putting an API key into Pi and using a hosted model is a very boring operation. You select the provider, paste the key and then you are done thinking about how to get tokens. Doing the same thing locally, even when you have a high-end Mac with a lot of memory, is a completely different experience. You choose an inference engine, then a model, then a quantization, then a template, then a context size, then you’ve got to throw a bunch of JSON configs into different parts of the stack and then you discover that one of those choices quietly made the model worse or that something just does not work at all.
That is the gap I am interested in.
Runnable Is Not Finished
A lot of local model work optimizes for making models runnable. That is necessary, but it is not the same thing as making them feel finished. I give you a very basic example here to illustrate this gap: tool parameter streaming.
For whatever reason, most of the stuff you run locally does not support tool parameter streaming. I cannot quite explain it, but the consequences of that are actually surprisingly significant. If you are not familiar with how these APIs work, the simplest way to think about them is that they are emitting tokens as they become available. For text that is trivial, but for tool calls that is often not done, despite the completions API supporting this. As a result you only see what edits are being done on a file once the model has finished streaming the entire tool call.
This is bad for a lot of reasons:
A dead connection is a weird connection: local models are slow, so when you don’t get any tokens for 5 minutes then you can’t tell if the connection died or just nothing came. This means you need to increase the inactivity timeouts to the point where they are pointless.
You won’t see what will happen: if you are somewhat hands-on, not seeing what bash invocation the system is concocting slowly in the background means potentially wasted tokens, and also means that you won’t be able to interrupt it until way too late.
It’s just not SOTA. We can do better, and we should aim for having the best possible experience. Tool parameter streaming is as important as token streaming in other places.
Having a model spit out tokens doesn’t take long, but making the experience great end to end does take a lot more energy.
Fragmentation
The local stack is fragmented across many engines and layers. There is llama.cpp, Ollama, LM Studio, MLX, Transformers, vLLM, and many other pieces depending on hardware and taste. All of these are amazing projects! The problem is not that they exist or that there are that many of them (even though, quite frankly, I’m getting big old Python packaging vibes), the problem is that for a given model, the actual behavior you get depends on a long chain of small decisions that most users just don’t have the energy for.
Did the chat template render exactly right? Are the reasoning tokens handled in the intended way? Is the tool-call format translated correctly? Is the context window real? Are the KV caches actually working for a coding agent? Did I pick the right quantized model from Hugging Face? Are you accidentally leaving a lot of performance on the table because the model is just mismatched for your hardware? Does streaming usage work across all channels? Does the model need its previous reasoning content preserved in assistant messages? Is the coding agent set up correctly for it?
You also need to install many different things in addition to just your coding agent.
All of these things matter. They matter a lot.
The result is that people try a local model and get a result that is neither a fair evaluation of the model nor a polished product experience and this results in both people dismissing local models and energy being distributed across way too many separate efforts instead of getting one effort going great end to end.
This is a terrible way to build confidence.
Too Little Critical Mass
In line with our general “slow the fuck down” mantra, I want to reiterate once more how fast this industry is moving.
Every week there is a new model and a new vibeslopped thing. The attention immediately moves to making the next thing run instead of making one thing run really, really well in one harness. I get the excitement and dopamine hit, but it also means that too little critical mass accumulates behind any one model, hardware, inference engine, harness combo to find out how good it can really become when the entire stack is built around it.
Hosted model providers do not ship a bag of weights and ask you to figure out the rest, and we need to approach that line of thinking for local models too. I want someone to pick one model, pairs it up with one serving path, directly within a coding agent. Initially just for one hardware configuration, then for more. Pick a winner hard. If a tool call breaks, that is a product bug and then it’s fixed no matter where in the stack it failed. If the model’s reasoning stream is malformed, that is a product bug. If latency is much worse than it should be, that is a product bug. We need to start applying that mentality to local models too.
And not for every model! That is the point. Let’s pick one winner and polish the hell out of it. Learn what it takes to make that one configuration good, then take those learnings to the next config.
The DS4 Bet
This is why I am excited about ds4.c . It’s Salvatore Sanfilippo’s deliberately narrow inference engine for DeepSeek V4 Flash on Macs with 128GB+ of RAM only. It is not a generic GGUF runner and it is not trying to be a framework. It is a model-specific native engine with a Metal path, model-specific loading, prompt rendering, KV handling, server API glue, and tests.
DeepSeek V4 Flash is a good candidate for this kind of experiment because it has a combination of properties that are unusual for local use. It is large enough to feel meaningfully different from many smaller dense models, but sparse enough that the active parameter count makes it plausible to run. It has a very large context window. Since ds4.c targets Macs and Metal only, it can move KV caches into SSDs which greatly helps the kind of workloads we expect from coding agents.
To run
ds4.cyou don’t need MLX, Ollama or anything else. It’s the whole package.Embedding It In Pi
Which made me build pi-ds4 which is a Pi extension to directly embed the whole thing into Pi itself. Taking what ds4 is and dogfooding the hell out of it with a coding agent and zero configuration. To answer the question how good can the local model experience become if Pi treats this as a first-class provider rather than as a pile of manual configuration?
The extension registers
ds4/deepseek-v4-flash, compiles and startsds4-serveron demand, downloads and builds the runtime if needed, chooses the quantization based on the machine, keeps a lease while Pi is using it, exposes logs, and shuts the server down again through a watchdog when no clients are left. It doesn’t even give you knobs right now, because I want to figure out how to set the knobs automatically.This is not about hiding the fact that local inference is complicated. It is about putting the complexity in one place where it can be improved, because there is a lot that we need to improve along the stack to make it work better.
I think we can do better with caching and there is probably some performance that can be gained if we all put our heads together.
Focusing and Learning
The experiment I want to run is not “can a local model run?” because we already know that it can. I want to know if, for people with beefed-out Macs for a start, we can get as close as possible to the ergonomics of a hosted provider with decent tool-calling performance: how to get caches to work well, how to improve the way we expose tools in harnesses for these models, and then scale it gradually to more hardware configs and later models.
I also want everybody to have access to this. Engineers need hammers and a hammer that’s locked behind a subscription in a data center in another country does not qualify. I know that the price tag on a Mac that can run this is itself astronomical, but I think it’s more likely that this will go down. Even worse, Apple right now due to the RAM shortage does not even sell the Mac Studio with that much RAM. So yes, it’s a selected group of people where ds4.c will start out.
But despite all of that, what matters is that a critical mass of pepole start to focus their efforts on a thing, tinker with it, improve it, not locked away, out in the open, and most importantly not limited by what the hyperscalers make available.
But if you have the right hardware and you care about local agents, I would love for you to try it within pi:
pi install https://github.com/mitsuhiko/pi-ds4My hope is that this becomes a useful forcing function to really polish one coding agent experience. But really, the focal point should be ds4.c itself .
Content for Content’s Sake
Published: Mon, 04 May 2026 00:00:00 +0000
Updated: Mon, 04 May 2026 00:00:00 +0000
UTC: 2026-05-04 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/5/4/content-for-contents-sake/Language is constantly evolving, particularly in some communities. Not everybody is ready for it at all times. I, for instance, cannot stand that my community is now constantly “cooking” or “cooked”, that people in it are “locked in” or “cracked.” I don’t like it, because the use of the words primarily signals membership of a group rather than one’s individuality.Content Preview
Language is constantly evolving, particularly in some communities. Not everybody is ready for it at all times. I, for instance, cannot stand that my community is now constantly “cooking” or “cooked”, that people in it are “locked in” or “cracked.” I don’t like it, because the use of the words primarily signals membership of a group rather than one’s individuality.
But some of the changes to that language might now be coming from … machines? Or maybe not. I don’t know. I, like many others, noticed that some words keep showing up more than before, and the obvious assumption is that LLMs are at fault. What I did was take 90 days’ worth of my local coding sessions and look for medium-frequency words where their use is inflated compared to what wordfreq would assume their frequency should be. Then I looked for the more common of these words and did a Google Trends search (filtered to the US). Note that some words like “capability” are more likely going to show up in coding sessions just because of the nature of the problem, so the actual increase is much more pronounced than you would expect.
You can click through it; this is what the change over time looks like. Note that these are all words from agent output in my coding sessions that are inflated compared to historical norms:
Loading word trend chart…
Something is going on for sure. Google Trends, in theory, reflects words that people search for. In theory, maybe agents are doing some of the Googling, but it might just be humans Googling for stuff that is LLM-generated; I don’t know. This data set might be a complete fabrication, but for all the words I checked and selected, I also saw an increase on Google Trends.
So how did I select the words to check in the first place? First, I looked for the highest-frequency words. They were, as you would expect, things like “add”, “commit”, “patch”, etc. Then I had an LLM generate a word list of words that it thought were engineering-related, and I excluded them entirely from the list. Then I also removed the most common words to begin with. In the end, I ended up with the list above, plus some other ones that are internal project names. For instance, habitat and absurd , as well as some other internal code names, were heavily over-represented, and I had to remove those. As you can see, not entirely scientific. But of the resulting list of words with a high divergence compared to wordfreq, they all also showed spikes on Google Trends.
There might also be explanations other than LLM generation for what is going on, but I at least found it interesting that my coding session spikes also show up as spikes on Google Trends.
The Rise of LLM Slop
The choice of words is one thing; the way in which LLMs form sentences is another. It’s not hard to spot LLM-generated text, but I’m increasingly worried that I’m starting to write like an LLM because I just read so much more LLM text. The first time I became aware of this was that I used the word “substrate” in a talk I gave earlier this year. I am not sure where I picked it up, but I really liked it for what I wanted to express and I did not want to use the word “foundation”. Since then, however, I am reading this word everywhere. This, in itself, might be a case of the Baader–Meinhof phenomenon , but you can also see from the selection above that my coding agent loves substrate more than it should, and that Google Trends shows an increase.
We have all been exposed to LLM-generated text now, but I feel like this is getting worse recently. A lot of the tweet replies I get and some of the Hacker News comments I see read like they are LLM-generated, and that includes people I know are real humans. It’s really messing with my brain because, on the one hand, I really want to tell people off for talking and writing like LLMs; on the other hand, maybe we all are increasingly actually writing and speaking like LLMs?
I was listening to a talk recording recently (which I intentionally will not link) where the speaker used the same sentence structure that is over-represented in LLM-generated text. Yes, the speaker might have used an LLM to help him generate the talk, but at the same time, the talk sounded natural. So either it was super well-rehearsed, or it was natural.
Engage and Farm
At least on Twitter, LinkedIn, and elsewhere, there is a huge desire among people to write content and be read. Shutting up is no longer an option and, as a result, people try to get reach and build their profile by engaging with anything that is popular or trending. In the same way that everybody has gazillions of Open Source projects all of a sudden, everybody has takes on everything.
My inbox is a disaster of companies sending me AI-generated nonsense and I now routinely see AI-generated blog posts (or at least ones that look like they are AI-generated) being discussed in earnest on Hacker News and elsewhere.
Genuine human discourse had already been an issue because of social media algorithms before, but now it has become incredibly toxic. As more and more people discover that they can use LLMs to optimize their following, they are entering an arms race with the algorithms and real genuine human signal is losing out quickly. There are entire companies now that just exist to automate sending LLM-generated shit and people evidently pay money for it.
Speed Should Kill
If we take into account the idea that the highest-quality content should win out, then the speed element would not matter. If a human-generated comment comes in 15 minutes after a clanker-generated one, but outperforms it by being better, then this whole LLM nonsense would show up less. But I think that LLM-generated noise actually performs really well. We see this plenty with Open Source now. Someone builds an interesting project, puts it on GitHub and within hours, there are “remixes” and “reimplementations” of that codebase. Not only that, many of those forks come with sloppy marketing websites, paid-for domains, and a whole story on socials about why this is the path to take.
I have complained before that Open Source is quickly deteriorating because people now see the opportunity to build products on top of useful Open Source projects, but the underlying mechanics are the same as why we see so much LLM slop. Someone has a formed opinion (hopefully) at lunch, and then has a clanker-made post 3 minutes later. It just does not take that much time to build it. For the tweets, I think it’s worse because I suspect that some people have scripts running to mostly automate the engagement.
And surely, we should hate all of this. These low-effort posts, tweets, and Open Source projects should not make it anywhere. But they do! Whatever they play into, whether in the algorithms or with human engagement, they are not punished enough for how little effort goes into them.
Friction and Rate Limiting
That increases in speed and ease of access can turn into problems is a long-understood issue. ID cards are a very unpopular thing in the UK because the British are suspicious of misuse of a central database after what happened in Nazi Germany. Likewise the US has the Firearm Owners Protection Act from 1986, which also bans the US from creating a central database of gun owners. The gun-tracing methodologies that result from not having such a database look like something out of a Wes Anderson movie . We have known for a long time that certain things should not be easy, because of the misuse that happens.
We know it in engineering; we know it when it comes to governmental overreach. Now we are probably going to learn the same lesson in many more situations because LLMs make almost anything that involves human text much easier. This is hitting existing text-based systems quickly. Take, for instance, the EU complaints system, which is now buckling under the pressure of AI . Or take any AI-adjacent project’s issue tracker. Pi is routinely getting AI-generated issue requests, sometimes even without the knowledge of the author .
Trust Erosion and Gaslighting
I know that’s a lot of complaining for “I am getting too many emails, shitty Twitter mentions, and GitHub issues.” I really think, though, that now that we know that it’s happening, we have to change how we interact with people who are increasingly automating themselves. Not only do they produce a lot of shitty slop that we all have to sit through; they are also influencing the world in much more insidious ways, in that they are influencing our interactions with each other. The moment I start distrusting people I otherwise trust, because they have started picking up LLM phrasing, it erodes trust all over society.
You also can’t completely ban people for bad behavior, because some of this increasingly happens accidentally. You sending Polsia spam to me? You’re dead to me. You sending me an AI-generated issue request and following up with an apology five minutes later? Well, I guess mistakes happen. Yet, in many ways, what is going on and will continue to go on is unsettling.
I recently talked with my friend Ben who said he forced someone to call him to continue a conversation because he was no longer convinced he was talking to a human.
Not all of us have been exposed to the extreme cases of this yet, but I had a handful of interactions in which I questioned reality due to the behavior of the person on the other side. I struggle with this, and I consider myself to be pretty open to new technologies and AI in particular. But how will my children react to stuff like this? My mother? I have strong doubts that technology is going to solve this for us.
Suggestions for Change
The reason I don’t think technology is going to solve this for us is that while it can hide some spam and label some generated text, it won’t fix us humans. What is being damaged here are social interactions across the board: the assumption that when someone writes to you, there is a person on the other side who has put some care into the interaction. I would rather have someone ghost me or reject me than send me back some AI-generated slop.
Change has to start with awareness and an unfortunate development is that LLMs don’t just influence the text we read and they influence the text we write, even when we don’t use them. Given the resulting ambiguity, we need to become more aware of how easily we can turn into energy vampires when we use agents to back us up in interactions with others. Consider that every time someone reads text coming from you, they will increasingly have to make a judgment call if it was you, an LLM, or you and an LLM that produced the interaction. Transparency in either direction, when there is ambiguity, can help great lengths.
When someone sends us undeclared slop, we need to change how we engage with them. If we care about them, we should tell them. If we don’t care about them, we should not give them visibility and not engage.
When it comes to creating platforms and interfaces where text can be submitted, we need to throw more wrenches in. The fact that it was cheap for you to produce does not make it cheap for someone else to receive, and we need to find more creative ways to increase the backpressure. GitHub or whatever wants to replace it, will have a lot to improve here and some of which might be going against its core KPIs. More engagement is increasingly the wrong thing to look at if you want a long term healthy platform.
Whatever we can do to rate-limit social interactions is something we should try: more in-person meetings, more platforms where trust has to be earned, and maybe more acceptance that sometimes the right response is no response at all.
And as for AI assistance on this blog, I have an AI transparency disclaimer for a while. In this particular blog post I used Pi as an agent to help me generate the dynamic visualization and I used to write the code to analyze and scrape Google Trends.
Before GitHub
Published: Tue, 28 Apr 2026 00:00:00 +0000
Updated: Tue, 28 Apr 2026 00:00:00 +0000
UTC: 2026-04-28 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/4/28/before-github/GitHub was not the first home of my Open Source software. SourceForge was.Content Preview
GitHub was not the first home of my Open Source software. SourceForge was .
Before GitHub, I had my own Trac installation. I had Subversion repositories, tickets, tarballs, and documentation on infrastructure I controlled. Later I moved projects to Bitbucket, back when Bitbucket still felt like a serious alternative place for Open Source projects, especially for people who were not all-in on Git yet.
And then, eventually, GitHub became the place, and I moved all of it there.
It is hard for me to overstate how important GitHub became in my life. A large part of my Open Source identity formed there. Projects I worked on found users there. People found me there, and I found other people there. Many professional relationships and many friendships started because some repository, issue, pull request, or comment thread made two people aware of each other.
That is why I find what is happening to GitHub today so sad and so disappointing. I do not look at it as just the folks at Microsoft making product decisions I dislike. GitHub was part of the social infrastructure of Open Source for a very long time. For many of us, it was not merely where the code lived; it was where a large part of the community lived.
So when I think about GitHub’s decline, I also think about what came before it, and what might come after it. I have written a few times over the years about dependencies, and in particular about the problem of micro dependencies . In my mind, GitHub gave life to that phenomenon. It was something I definitely did not completely support, but it also made Open Source more inclusive. GitHub changed how Open Source feels, and later npm and other systems changed how dependencies feel. Put them together and you get a world in which publishing code is almost frictionless, consuming code is almost frictionless, and the number of projects in the world explodes.
That has many upsides. But it is worth remembering that Open Source did not always work this way.
A Smaller World
Before GitHub, Open Source was a much smaller world. Not necessarily in the number of people who cared about it, but in the number of projects most of us could realistically depend on.
There were well-known projects, maintained over long periods of time by a comparatively small number of people. You knew the names . You knew the mailing lists. You knew who had been around for years and who had earned trust. That trust was not perfect, and the old world had plenty of gatekeeping, but reputation mattered in a very direct way. We took pride (and got frustrated) when the Debian folks came and told us our licensing stuff was murky or the copyright headers were not up to snuff, because they packaged things up.
A dependency was not just a package name. It was a project with a history, a website, a maintainer, a release process, a lot of friction, and often a place in a larger community. You did not add dependencies casually, because the act of depending on something usually meant you had to understand where it came from.
Not all of this was necessarily intentional, but because these projects were comparatively large, they also needed to bring their own infrastructure. Small projects might run on a university server, and many of them were on SourceForge, but the larger ones ran their own show. They grouped together into larger collectives to make it work.
We Ran Our Own Infrastructure
My first Open Source projects lived on infrastructure I ran myself. There was a Trac installation, Subversion repositories, tarballs, documentation, and release files served from my own machines or from servers under my control. That was normal. If you wanted to publish software, you often also became a small-time system administrator. Georg and I ran our own collective for our Open Source projects: Pocoo . We shared server costs and the burden of maintaining Subversion and Trac, mailing lists and more.
Subversion in particular made this “running your own forge” natural. It was centralized: you needed a server, and somebody had to operate it. The project had a home, and that home was usually quite literal: a hostname, a directory, a Trac instance, a mailing list archive.
When Mercurial and Git arrived, they were philosophically the opposite. Both were distributed. Everybody could have the full repository. Everybody could have their own copy, their own branches, their own history. In principle, those distributed version control systems should have reduced the need for a single center. But despite all of this, GitHub became the center.
That is one of the great ironies of modern Open Source. The distributed version control system won, and then the world standardized on one enormous centralized service for hosting it.
What GitHub Gave Us
It is easy now to talk only about GitHub’s failures, of which there are currently many, but that would be unfair: GitHub was, and continues to be, a tremendous gift to Open Source.
It made creating a project easy and it made discovering projects easy. It made contributing understandable to people who had never subscribed to a development mailing list in their life. It gave projects issue trackers, pull requests, release pages, wikis, organization pages, API access, webhooks, and later CI. It normalized the idea that Open Source happens in the open, with visible history and visible collaboration. And it was an excellent and reasonable default choice for a decade.
But maybe the most underappreciated thing GitHub did was archival work: GitHub became a library. It became an index of a huge part of the software commons because even abandoned projects remained findable. You could find forks, and old issues and discussions all stayed online. For all the complaints one can make about centralization, that centralization also created discoverable memory. The leaders there once cared a lot about keeping GitHub available even in countries that were sanctioned by the US.
I know what the alternative looks like, because I was living it. Some of my earliest Open Source projects are technically still on PyPI , but the actual packages are gone. The metadata points to my old server, and that server has long stopped serving those files.
That was normal before the large platforms. A personal domain expired, a VPS was shut down, a developer passed away, and with them went the services they paid for. The web was once full of little software homes, and many of them are gone 1 .
npm and the Dependency Explosion
The micro-dependency problem was not just that people published very small packages. The hosted infrastructure of GitHub and npm made it feel as if there was no cost to create, publish, discover, install, and depend on them.
In the pre-GitHub world, reputation and longevity were part of the dependency selection process almost by necessity, and it often required vendoring. Plenty of our early dependencies were just vendored into our own Subversion trees by default, in part because we could not even rely on other services being up when we needed them and because maintaining scripts that fetched them, in the pre-API days, was painful. The implied friction forced some reflection, and it resulted in different developer behavior. With npm-style ecosystems, the package graph can grow faster than anybody’s ability to reason about it.
The problem that this type of thinking created also meant that solutions had to be found along the way. GitHub helped compensate for the accountability problem and it helped with licensing. At one point, the newfound influx of developers and merged pull requests left a lot of open questions about what the state of licenses actually was. GitHub even attempted to rectify this with their terms of service.
The thinking for many years was that if I am going to depend on some tiny package, I at least want to see its repository. I want to see whether the maintainer exists, whether there are issues, whether there were recent changes, whether other projects use it, whether the code is what the package claims it is. GitHub became part of the system that provides trust, and more recently it has even become one of the few systems that can publish packages to npm and other registries with trusted publishing.
That means when trust in GitHub erodes, the problem is not isolated to source hosting. It affects the whole supply chain culture that formed around it.
GitHub Is Slowly Dying
GitHub is currently losing some of what made it feel inevitable. Maybe that’s just the life and death of large centralized platforms: they always disappoint eventually. Right now people are tired of the instability, the product churn, the Copilot AI noise, the unclear leadership, and the feeling that the platform is no longer primarily designed for the community that made it valuable.
Obviously, GitHub also finds itself in the midst of the agentic coding revolution and that causes enormous pressure on the folks over there. But the site has no leadership! It’s a miracle that things are going as well as they are.
For a while, leaving GitHub felt like a symbolic move mostly made by smaller projects or by people with strong views about software freedom. I definitely cringed when Zig moved to Codeberg! But I now see people with real weight and signal talking about leaving GitHub. The most obvious one is Mitchell Hashimoto, who announced that Ghostty will move . Where it will move is not clear, but it’s a strong signal. But there are others, too. Strudel moved to Codeberg and so did Tenacity . Will they cause enough of a shift? Probably not, but I find myself on non-GitHub properties more frequently again compared to just a year ago.
One can argue that this is good: it is healthy for Open Source to stop pretending that one company should be the default home of everything. Git itself was designed for a world with many homes.
Dispersion Has a Cost
Going back to many forges, many servers, many small homes, and many independent communities will increase decentralization, and in many ways it will force systems to adapt. This can restore autonomy and make projects less dependent on the whims of Microsoft leadership. It can also allow different communities to choose different workflows. What’s happening in Pi ‘s issue tracker currently is largely a result of GitHub’s product choices not working in the present-day world of Open Source. It was built for engagement, not for maintainer sanity.
It can also make the web forget again. I quite like software that forgets because it has a cleansing element. Maybe the real risk of loss will make us reflect more on actually taking advantage of a distributed version control system.
But if projects move to something more akin to self-hosted forges, to their own self-hosted Mercurial or cgit servers, we run the risk of losing things that we don’t want to lose. The code might be distributed in theory, but the social context often is not. Issues, reviews, design discussions, release notes, security advisories, and old tarballs are fragile. They disappear much more easily than we like to admit. Mailing lists, which carried a lot of this in earlier years, have not kept up with the needs of today, and are largely a user experience disaster.
We Need an Archive
As much as I like the idea of things fading out of existence, we absolutely need libraries and archives.
Regardless of whether GitHub is here to stay or projects find new homes, what I would like to see is some public, boring, well-funded archive for Open Source software. Something with the power of an endowment or public funding to keep it afloat. Something whose job is not to win the developer productivity market but just to make sure that the most important things we create do not disappear.
The bells and whistles can be someone else’s problem, but source archives, release artifacts, metadata, and enough project context to understand what happened should be preserved somewhere that is not tied to the business model or leadership mood of a single company.
GitHub accidentally became that archive because it became the center of Open Source activity. Once that no longer holds, we should not assume some magic archival function will emerge or that GitHub will continue to function as such. We have already seen what happens when project homes are just personal servers and good intentions, and we have seen what happened to Google Code and Bitbucket.
I hope GitHub recovers, I really do, in part because a lot of history lives there and because the people still working on it inherited something genuinely important. But I no longer think it is responsible to let the continued memory of Open Source depend on GitHub remaining a healthy product.
The world before GitHub had more autonomy and more loss, and in some ways, we’re probably going to move back there, at least for a while. Whatever people want to start building next should try to keep the memory and lose the dependence. It should be easier to move projects, easier to mirror their social context, easier to preserve releases, and harder for one company’s drift to become a cultural crisis for everyone else.
I do not want to go back to the old web of broken tarball links and abandoned Trac instances. I also do not want Open Source to pretend that the last twenty years were normal or permanent. GitHub wrote a remarkable chapter of Open Source, and if that chapter is ending, the next one should learn from it and also from what came before.
This is also a good reminder that we rely so very much on the Internet Archive for many projects of the time. ↩
Equity for Europeans
Published: Thu, 23 Apr 2026 00:00:00 +0000
Updated: Thu, 23 Apr 2026 00:00:00 +0000
UTC: 2026-04-23 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/4/23/equity-for-europeans/If you spend enough time in US business or finance conversations, one word keeps showing up: equity.Content Preview
If you spend enough time in US business or finance conversations, one word keeps showing up: equity .
Coming from a German-speaking, central European background, I found it surprisingly hard to fully internalize what that word means. More than that, I find it very hard to talk with other Europeans about it. Worst of all it’s almost impossible to explain it in German without either sounding overly technical or losing an important part of the meaning.
This post is in English, but it is written mostly for readers in Germany, Austria, and Switzerland, and more broadly for people from continental Europe. I move between “German-speaking” and “continental European” a bit. They are not the same thing, of course, but many continental European countries share a civil-law background that differs sharply from the English common-law and equity tradition. The words differ by language and jurisdiction, but the conceptual gap I am interested in shows up in similar ways.
In US usage, the word “equity” appears everywhere:
- real estate: “build equity in your home”
- startups: “employees get equity”
- public markets: “equity investors”
- private deals: “take an equity stake”
- personal finance: “negative equity in a car”
- social policy: “diversity, equity, and inclusion”
If you try to translate this into German, you have to choose words. Of course we can say Eigenkapital , Beteiligung , Anteil , Vermögen , Nettovermögen , or sometimes Substanzwert . In narrow contexts, each can be correct, but none of them carries the full concept. I find that gap interesting, because language affects default behavior and how we think about things.
One Word, Shared Meanings
In the English language, “equity” often carries multiple things at once. I believe the following ones to be the most important ones:
- A legal-fairness dimension: historically tied to equity in law
- A financial-accounting dimension: residual value after debt
- A cultural dimension: ownership as a path to wealth and agency
If you open Wikipedia, you will find many more distinct meanings of equity, but they all relate to much the same concept, just from different angles.
German, on the other hand, can express each of these layers precisely, including the subtleties within each, but it uses different words and there is no common, everyday umbrella word that naturally bundles all three.
When a concept has one short, reusable, positive word, people can move it across contexts very easily. When the concept is split into technical fragments, it tends to stay technical, and people do not necessarily think of these things as related at all in a continental European context.
How Equity Got Here
What is hard for Europeans to understand is how the financial meaning of equity appeared, because it did not appear out of nowhere. The word’s original meaning comes from fairness or impartiality, and it made it to modern English via Old French and Latin ( equité / aequitas ).
Historically, English law had separate traditions: common law courts and courts of equity (especially the Court of Chancery ). Equity in law was about fairness, conscience, and remedies where strict common law rules were too rigid. Take mortgages for instance: in older English practice, a mortgage could transfer title as security. Under strict common law, missing a deadline could mean losing the property entirely. Courts of equity developed the “ equity of redemption ”: a borrower could still redeem by paying what was owed.
That equitable interest became foundational for how ownership and claims were understood. In finance, equity came to mean not just a number, but a claim: the residual owner’s stake after prior claims are satisfied.
The European Split
German and continental European legal development took a different path. Civil law systems did not build the same separate institutional track of “equity courts” versus common law courts. Fairness principles absolutely exist, but inside the codified system, not as a parallel jurisdiction with its own language and mythology.
As a result, German vocabulary has many different words, and they are highly domain-specific. There are equivalents in other languages, and to some degree they exist in English too:
- company balance sheet: Eigenkapital
- ownership share: Beteiligung , Anteil
- unrealized asset value: stille Reserven
- household wealth: Vermögen , Nettovermögen
- investment action: Anlage , Investition
- residual net assets: Reinvermögen
This precision is useful for legal drafting and accounting. But it also means we have less of the shared mental package that many Americans get from “equity”: own a piece, carry risk, participate in upside, build wealth.
Schuld Is Not Just Debt
There is another linguistic oddity worth noting: in German, “Schuld” can mean both debt/liability and guilt, and I think that too has changed how we think about equity.
“Schuld” in everyday language makes debt feel more morally charged than it does in the US. Indebtedness is often framed as a burden, and it is not thought of as a tool at all.
US financial language, by contrast, often frames debt more instrumentally and pairs it with an explicit positive counterpart: equity. Equity is what is yours after debt, what can appreciate, what can be transferred, and what can give you control.
In American financial language, debt is not as morally burdened, and equity is more than the absence of debt: it is the positive claim on the balance sheet — ownership, optionality, control, and upside.
Practical Matters
If you grew up with German-speaking framing, many US statements around equity can sound ideological or naive. From a continental European lens, they can sound like imported jargon or hollow. But if we ignore the concept, we lose something practical:
- We discuss salaries in cash terms but under-discuss ownership.
- We treat employee participation as exotic instead of normal.
- We under-explain compounding and intergenerational transfer.
- We miss a language for talking about agency through ownership.
I am not saying German-speaking Europeans are incapable of this mindset. Obviously we are not. But we clearly tend to think about these things differently.
Normalize Equity
When you hear “equity,” it helps to think of it as a rightful stake. Historically, it is connected to fairness and the recognition of a claim where strict rules would be too rigid. Financially, it is the part that remains after prior obligations. Culturally, it is something that can grow into control, agency, and upside.
That is not a perfect definition, but it captures why the term is so sticky in American discourse. It combines a present claim with a future possibility. It is not just what remains after debt; it is the part that can grow, compound, and give you agency.
If Europeans want to talk more seriously about entrepreneurship, retirement, housing, and wealth building, we would benefit from a stronger everyday vocabulary for exactly this idea. We need a longing for equity so that ownership does not remain something for founders, lawyers, accountants, and wealthy families, but becomes a normal part of how people think about work, risk, and their future.
Not because we should imitate America, but because this mental model helps people make clearer decisions about ownership, incentives, and long-term agency. For Europe, that shift feels long overdue .
The Center Has a Bias
Published: Sat, 11 Apr 2026 00:00:00 +0000
Updated: Sat, 11 Apr 2026 00:00:00 +0000
UTC: 2026-04-11 00:00:00+00:00
URL: https://lucumr.pocoo.org/2026/4/11/the-center-has-a-bias/Whenever a new technology shows up, the conversation quickly splits into camps. There are the people who reject it outright, and there are the people who seem to adopt it with religious enthusiasm. For more than a year now, no topic has been more polarising than AI coding agents.Content Preview
Whenever a new technology shows up, the conversation quickly splits into camps. There are the people who reject it outright, and there are the people who seem to adopt it with religious enthusiasm. For more than a year now, no topic has been more polarising than AI coding agents.
What I keep noticing is that a lot of the criticism directed at these tools is perfectly legitimate, but it often comes from people without a meaningful amount of direct experience with them. They are not necessarily wrong. In fact, many of them cite studies, polls and all kinds of sources that themselves spent time investigating and surveying. And quite legitimately they identified real issues: the output can be bad, the security implications are scary, the economics are strange and potentially unsustainable, there is an environmental impact, the social consequences are unclear, and the hype is exhausting.
But there is something important missing from that criticism when it comes from a position of non-use: it is too abstract.
There is a difference between saying “this looks flawed in principle” and saying “I used this enough to understand where it breaks, where it helps, and how it changes my work.” The second type of criticism is expensive. It costs time, frustration, and a genuine willingness to engage.
The enthusiast camp consists of true believers. These are the people who have adopted the technology despite its shortcomings, sometimes even because they enjoy wrestling with them. They have already decided that the tool is worth fitting into their lives, so they naturally end up forgiving a lot. They might not even recognize the flaws because for them the benefits or excitement have already won.
But what does the center look like? I consider myself to be part of the center: cautiously excited, but also not without criticism. By my observation though that center is not neutral in the way people imagine it to be. Its bias is not towards endorsement so much as towards engagement, because the middle ground between rejecting a technology outright and embracing it fully is usually occupied by people willing to explore it seriously enough to judge it.
Bias on Both Sides
The compositions of the groups of people in the discussions about new technology are oddly shaped because one side has paid the cost of direct experience and the other has not, or not to the same degree. That alone creates an asymmetry.
Take coding agents as an example. If you do not use them, or at least not for productive work, you can still criticize them on many grounds. You can say they generate sloppy code, that they lower your skills, etc. But if you have not actually spent serious time with them, then your view of their practical reality is going to be inherited from somewhere else. You will know them through screenshots, anecdotes, the most annoying users on Twitter, conference talks, company slogans, and whatever filtered back from the people who did use them. That is not nothing, but it is not the same as contact.
The problem is not that such criticism is worthless. The problem is that people often mistake non-use for neutrality. It is not. A serious opinion on a new language, framework, device, or way of working usually has some minimum buy-in. You have to cross a threshold of use before your criticism becomes grounded in the thing itself rather than in its reputation.
That threshold is inconvenient. It asks you to spend time on something that may not pay off, and to risk finding yourself at least partially won over. It is a lot to ask of people. But because that threshold exists, the measured middle is rarely populated by people who are perfectly indifferent to change. It is populated by people who were willing to move toward it enough in order to evaluate it properly.
Simultaneously, it’s important to remember that usage does not automatically create wisdom. The enthusiastic adopter might have their own distortions. They may enjoy the novelty, feel a need to justify the time they invested, or overgeneralize from the niche where the technology works wonderfully. They may simply like progress and want to be associated with it.
This is particularly visible with AI. There are clearly people who have decided that the future is here, all objections are temporary, and every workflow must now be rebuilt around agents. What makes AI weirder is that it’s such a massive shift in capabilities that has triggered a tremendous injection of money, and a meaningful number of adopters have bet their future on that technology.
So if one pole is uninformed abstraction and the other is overcommitted enthusiasm, then surely the center must sit right in the middle between them?
Engagement Is Not Endorsement
The center, I would argue, naturally needs to lean towards engagement. The reason is simple: a genuinely measured opinion on a new technology requires real engagement with it.
You do not get an informed view by trying something for 15 minutes, getting annoyed once, and returning to your previous tools. You also do not get it by admiring demos, listening to podcasts or discussing on social media. You have to use it enough to get past both the first disappointment and the honeymoon phase. Seemingly with AI tools, true understanding is not a matter of hours but weeks of investment.
That means the people in the center are selected from a particular group: people who were willing to give the thing a fair chance without yet assuming it deserved a permanent place in their lives.
That willingness is already a bias towards curiosity and experimentation which makes the center look more like adopters in behavior, because exploration requires use, but it does not make the center identical to enthusiasts in judgment.
This matters because from the perspective of the outright rejecter, all of these people can look the same. If someone spent serious time with coding agents, found them useful in some areas, harmful in others, and came away with a nuanced view, they may still be thrown into the same bucket as the person who thinks agents can do no wrong.
But those are not the same position at all. It’s important to recognize that engagement with those tools does not automatically imply endorsement or at the very least not blanket endorsement.
The Center Looks Suspicious
This is why discussions about new technology, and AI in particular feel so polarized. The actual center is hard to see because it does not appear visually centered. From the outside, serious exploration can look a lot like adoption.
If you map opinions onto a line, you might imagine the middle as the point equally distant from rejection and enthusiasm. But in practice that is not how it works. The middle is shifted toward the side of the people who have actually interacted with the technology enough to say something concrete about it. That does not mean the middle has accepted the adopter’s conclusion. It means the middle has adopted some of the adopter’s behavior, because investigation requires contact.
That creates a strange effect because the people with the most grounded criticism are often also adopters. I would argue some of the best criticism of coding agents right now comes from people who use them extensively. Take Mario : he created a coding agent, yet is also one of the most vocal voices of criticism in the space. These folks can tell you in detail how they fail and they can tell you where they waste time, where they regress code quality, where they need carefully designed tooling, where they only work well in some ecosystems, and where the whole thing falls apart.
But because those people kept using the tools long enough to learn those lessons, they can appear compromised to outsiders. And worse: if they continue to use them, contribute thoughts and criticism back, they are increasingly thrown in with the same people who are devoid of any criticism.
Failure Is Possible
This line of thinking could be seen as an inherent “pro-innovation bias.” That would be wrong, as plenty of technology deserves resistance. Many people are right to resist, and sometimes the people who never gave a technology a chance saw problems earlier than everyone else. Crypto is a good reminder: plenty of projects looked every bit as exciting as coding agents do now, and still collapsed when the economics no longer worked.
What matters here is a narrower point. The center is not biased towards novelty so much as towards contact with the thing that creates potential change. The middle ground is not between use and non-use, but between refusal and commitment and the people in the center will often look more like adopters than skeptics, not because they have already made up their minds, but because getting an informed view requires exploration.
If you want to criticize a new thing well, you first have to get close enough to dislike it for the right reasons. And for some technologies, you also have to hang around long enough to understand what, exactly, deserves criticism.