Last week, I got a LinkedIn message from a recruiter at a small crypto startup. We exchanged a few messages over a couple of days, she described a broken proof-of-concept they needed a lead engineer for, and then sent me a public GitHub repo to review. Specifically, she asked me to “check out the deprecated Node modules issue.”
It’s not uncommon to ask for a review of an existing codebase, but something felt off and raised an alarm in my head, so I decided to get a bit extra paranoid.
Content Preview
Last week, I got a LinkedIn message from a recruiter at a small crypto startup. We exchanged a few messages over a couple of days, she described a broken proof-of-concept they needed a lead engineer for, and then sent me a public GitHub repo to review. Specifically, she asked me to “check out the deprecated Node modules issue.”
It’s not uncommon to ask for a review of an existing codebase, but something felt off and raised an alarm in my head, so I decided to get a bit extra paranoid.
This is the sixth take on the same news reader. Previous versions used tool-calling agents. This time I used smolagents from HuggingFace, specifically its CodeAgent. Instead of calling predefined tools, the agent writes Python code and executes it in a sandbox.
How CodeAgent works
A CodeAgent follows a ReAct loop: think, act, observe, repeat. At each step, the LLM generates a Python snippet, the framework executes it, and stdout plus the return value feed back as the next observation. To finish, the agent calls final_answer(value).
Content Preview
This is the sixth take on the same news reader. Previous versions used tool-calling agents. This time I used
smolagents
from HuggingFace, specifically its
CodeAgent
. Instead of calling predefined tools, the agent writes Python code and executes it in a sandbox.
How CodeAgent works
A CodeAgent follows a
ReAct loop
: think, act, observe, repeat. At each step, the LLM generates a Python snippet, the framework executes it, and stdout plus the return value feed back as the next observation. To finish, the agent calls
final_answer(value)
.
This is the fifth take on the same news reader. The Claude Agent SDK version was a single Python file with tools and sub-agents. The Pi SDK version was a single TypeScript file with an event-based session. This time I used Pydantic AI, the agent framework from the Pydantic team.
Pydantic AI’s pitch is that since every AI library already depends on Pydantic for validation, you might as well build agents directly on it. The result feels like FastAPI for agents: decorators, type annotations, and automatic schema generation.
Content Preview
This is the fifth take on the same news reader. The
Claude Agent SDK version
was a single Python file with tools and sub-agents. The
Pi SDK version
was a single TypeScript file with an event-based session. This time I used
Pydantic AI
, the agent framework from the Pydantic team.
Pydantic AI’s pitch is that since every AI library already depends on Pydantic for validation, you might as well build agents directly on it. The result feels like FastAPI for agents: decorators, type annotations, and automatic schema generation.
Agent engineering: Pi SDK
Published: Sun, 07 Jun 2026 10:00:00 +0000
Updated: Sun, 07 Jun 2026 10:00:00 +0000 UTC: 2026-06-07 10:00:00+00:00
URL: https://roman.pt/posts/pi-sdk-version/
In the previous post, I built a news reader using Pi’s CLI with an extension file and a system prompt file. Two files in a .pi/ directory, run with pi -p. It already felt minimal compared to the Claude Code version, but it still relied on Pi’s runtime to discover and load the extension.
Pi also has a programmatic SDK that lets you embed the agent in your own script, the same way the Agent SDK let me collapse the Claude Code version into a single Python file.
Content Preview
In the
previous post
, I built a news reader using Pi’s CLI with an extension file and a system prompt file. Two files in a
.pi/
directory, run with
pi -p
. It already felt minimal compared to the Claude Code version, but it still relied on Pi’s runtime to discover and load the extension.
Pi also has a
programmatic SDK
that lets you embed the agent in your own script, the same way the
Agent SDK
let me collapse the Claude Code version into a single Python file.
Agent engineering: Pi
Published: Sun, 07 Jun 2026 09:00:00 +0000
Updated: Sun, 07 Jun 2026 09:00:00 +0000 UTC: 2026-06-07 09:00:00+00:00
URL: https://roman.pt/posts/pi-dev-version/
I don’t know Pi well. I used it for a few small tasks and appreciated how minimal it felt. My news reader has become my test task for trying different agent tools against the same problem, so I rebuilt it with Pi to explore further. My opinions here may not survive deeper use, but the way I think about it: Claude Code is Django, Pi is Flask.
Claude Code ships with WebFetch, WebSearch, sub-agents, MCP support, a permissions system, and a whole settings infrastructure. You get a lot for free. The tradeoff is that you can’t easily remove what you don’t need. You may not use MCP or sub-agents, but they’re still there in the system prompt and the runtime. Like Django’s ORM, you lose more from fighting the built-in pieces than from just using them.
Content Preview
I don’t know
Pi
well. I used it for a few small tasks and appreciated how minimal it felt. My
news reader
has become my test task for trying different agent tools against the same problem, so I rebuilt it with Pi to explore further. My opinions here may not survive deeper use, but the way I think about it: Claude Code is Django, Pi is Flask.
Claude Code ships with WebFetch, WebSearch, sub-agents, MCP support, a permissions system, and a whole settings infrastructure. You get a lot for free. The tradeoff is that you can’t easily remove what you don’t need. You may not use MCP or sub-agents, but they’re still there in the system prompt and the runtime. Like Django’s ORM, you lose more from fighting the built-in pieces than from just using them.
In the previous post, I built a news reader that uses Claude Code as its execution environment. It worked well, but the project was spread across half a dozen config files, each in a different directory, connected by naming conventions. Changing anything meant knowing where each piece lived and how they were wired together.
That post ended with a teaser about the Claude Agent SDK and a five-line script that wraps the existing project. That was the lazy migration. This post goes the other direction: throw away the scaffolding and rebuild from scratch as a single Python file.
Content Preview
In
the previous post
, I built a news reader that uses Claude Code as its execution environment. It worked well, but the project was spread across half a dozen config files, each in a different directory, connected by naming conventions. Changing anything meant knowing where each piece lived and how they were wired together.
That post ended with a teaser about the
Claude Agent SDK
and a five-line script that wraps the existing project. That was the lazy migration. This post goes the other direction: throw away the scaffolding and rebuild from scratch as a single Python file.
I started with LLMs as another third-party dependency. In my apps, code defined the logic, and LLM calls handled small things like summarizing or tagging input. Over time, as agents gained more of my trust, I started experimenting with turning the execution model inside out.
Instead of code that occasionally calls an LLM, I use the agent loop as the execution environment itself. The agent drives the flow, and deterministic code only shows up where I actually need hard logic: structured storage and external API calls. Instead of being the main driver, Python becomes a small fraction of the overall logic.
Content Preview
I started with LLMs as another third-party dependency. In my apps, code defined the logic, and LLM calls handled small things like summarizing or tagging input. Over time, as agents gained more of my trust, I started experimenting with turning the execution model inside out.
Instead of code that occasionally calls an LLM, I use the agent loop as the execution environment itself. The agent drives the flow, and deterministic code only shows up where I actually need hard logic: structured storage and external API calls. Instead of being the main driver, Python becomes a small fraction of the overall logic.
Committing .idea directory
I never bothered committing .idea files before. Actually, I very much preferred treating it as a scary black box full of XML gibberish that I’d rather not touch.
It was fine back in the days when I had a stable set of projects, each configured once in PyCharm, and that was it. Adopting git worktrees changed my workflow: every worktree is a new directory, and PyCharm treats it as a new project that needs to be configured from scratch. So I decided to finally look inside and see what can be committed.
Content Preview
Committing .idea directory
I never bothered committing
.idea
files before. Actually, I very much preferred treating it as a scary black box full of XML gibberish that I’d rather not touch.
It was fine back in the days when I had a stable set of projects, each configured once in PyCharm, and that was it. Adopting git worktrees changed my workflow: every worktree is a new directory, and PyCharm treats it as a new project that needs to be configured from scratch. So I decided to finally look inside and see what can be committed.
I use two notification matchers:
permission_prompt
and
elicitation_dialog
. I used to have an
idle_prompt
matcher, but I removed it quite fast. When you run multiple agents, after a while they all start complaining they’re bored.
Smello for HTTP Requests
Published: Mon, 02 Mar 2026 00:00:00 +0000
Updated: Mon, 02 Mar 2026 00:00:00 +0000 UTC: 2026-03-02 00:00:00+00:00
URL: https://roman.pt/posts/smello/
Good news, everyone. I invented a smell-o-scope.
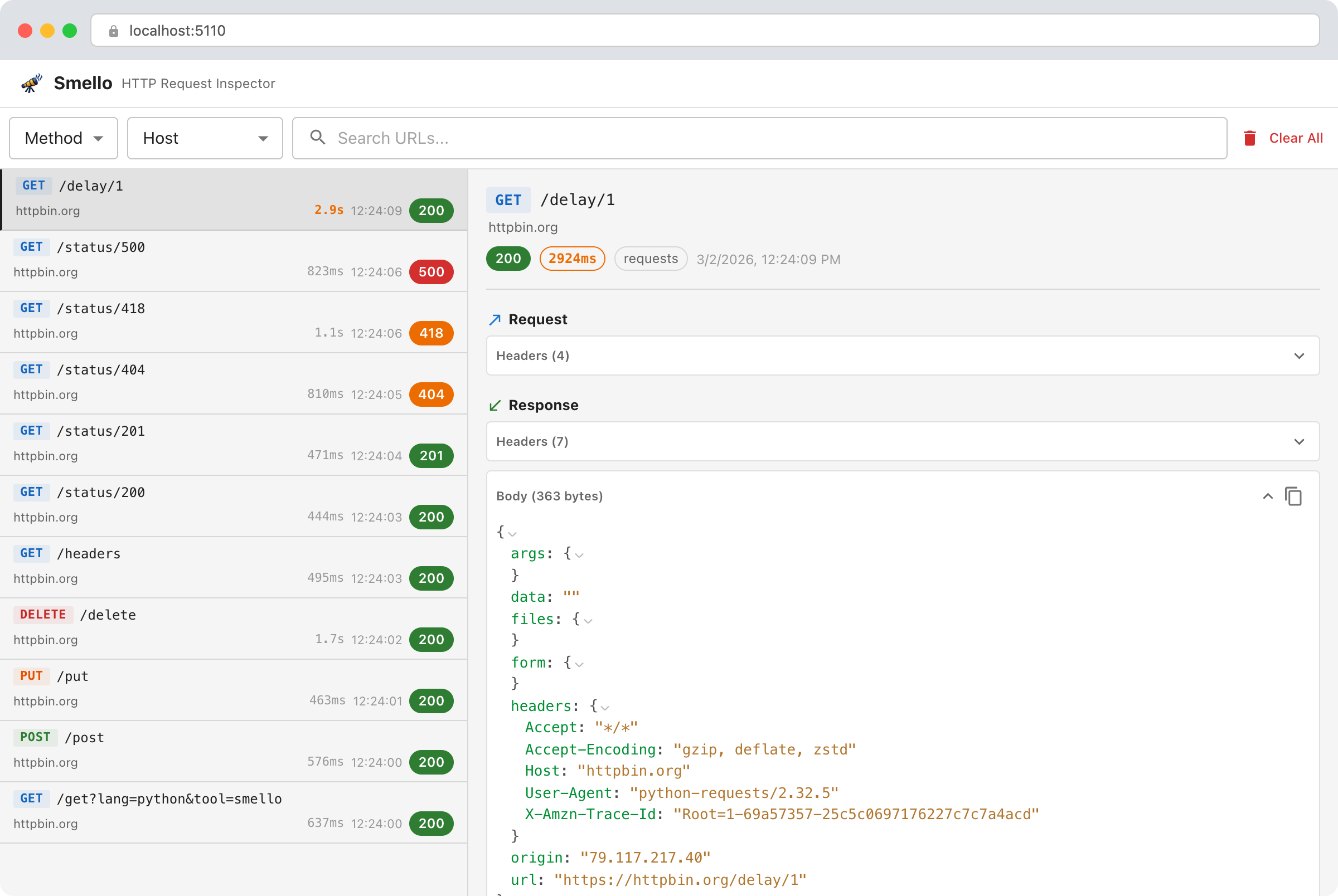
Smello captures outgoing HTTP requests from Python and displays them in a local web dashboard. It’s like Mailpit for HTTP.
The whole setup is two lines of code:
import smello
smello.init()
The Smello dashboard. Captured requests on the left, details on the right.
My problem
I work with external integrations a lot. Some of these APIs have great documentation, but the majority don’t. This is especially painful for those enterprise “contact us for pricing” services. With some exceptions, their documentation is awful. Usually, they send you something like a large outdated PDF, incomplete and poorly formatted, available by request. If you’re a contractor, you may not even have that luxury. All you have is a Confluence page where someone left some internal notes for their future self. In this situation, the most reliable way to learn these APIs is to call them and look at what comes back.
Content Preview
Good news, everyone. I invented a smell-o-scope.
Smello
captures outgoing HTTP requests from Python and displays them in a local web dashboard. It’s like
Mailpit
for HTTP.
The whole setup is two lines of code:
importsmellosmello.init()
The Smello dashboard. Captured requests on the left, details on the right.
My problem
I work with external integrations a lot. Some of these APIs have great documentation, but the majority don’t. This is especially painful for those enterprise “contact us for pricing” services. With some exceptions, their documentation is awful. Usually, they send you something like a large outdated PDF, incomplete and poorly formatted, available by request. If you’re a contractor, you may not even have that luxury. All you have is a Confluence page where someone left some internal notes for their future self. In this situation, the most reliable way to learn these APIs is to call them and look at what comes back.
Fixing Keyboard Input in tmux
Published: Thu, 12 Feb 2026 00:00:00 +0000
Updated: Thu, 12 Feb 2026 00:00:00 +0000 UTC: 2026-02-12 00:00:00+00:00
URL: https://roman.pt/posts/terminal-setup/
Two independent things happened that drove me to reconsider my terminal workflow.
First, I started relying more and more on Claude Code as my AI coding assistant running inside the terminal. Shift+Enter (for inserting newlines without submitting) didn’t work inside tmux, so I had to use a workaround. It was annoying, but acceptable.
Then I switched to a 96-key keyboard with dual Bluetooth, because I wanted a single keyboard that can switch between two computers. That’s when my tmux scrollback navigation broke too. With two things broken, I decided to look deeper into both issues and understand what’s actually going on.
Content Preview
Two independent things happened that drove me to reconsider my terminal workflow.
First, I started relying more and more on Claude Code as my AI coding assistant running inside the terminal. Shift+Enter (for inserting newlines without submitting) didn’t work inside tmux, so I had to use a workaround. It was annoying, but acceptable.
Then I switched to a 96-key keyboard with dual Bluetooth, because I wanted a single keyboard that can switch between two computers. That’s when my tmux scrollback navigation broke too. With two things broken, I decided to look deeper into both issues and understand what’s actually going on.
Recently, I noticed a shift in how I use coding agents. I switched from Cursor to Claude Code, spending more time in the console than in an IDE.
I started feeling comfortable offloading larger chunks of work to agents, steering them at a higher level and writing less code by hand. Simon Willison noticed something similar: the models got incrementally better, until GPT-5.2 and Opus 4.5 reached an inflection point where suddenly much harder coding problems opened up.
Content Preview
Recently, I noticed a shift in how I use coding agents. I switched from Cursor to Claude Code, spending more time in the console than in an IDE.
I started feeling comfortable offloading larger chunks of work to agents, steering them at a higher level and writing less code by hand. Simon Willison noticed something similar: the models got incrementally better, until GPT-5.2 and Opus 4.5 reached an inflection point where suddenly much harder coding problems opened up.
In this post, I’m diving into what Cursor, the AI Code Editor, does behind the scenes when I ask it to write code for me. My main goal is to figure out how to craft my prompts for the best results and see if there’s a better way to tap into its workflow.
It turns out that Cursor’s prompt structure reveals a lot about how it operates and how to set it up for maximum performance.
Content Preview
In this post, I’m diving into what Cursor, the AI Code Editor, does behind the scenes when I ask it to write code for me. My main goal is to figure out how to craft my prompts for the best results and see if there’s a better way to tap into its workflow.
It turns out that Cursor’s prompt structure reveals a lot about how it operates and how to set it up for maximum performance.
When working on external integrations, we often implement basic error handling. Most of the time, we just use resp.raise_for_status() and leave it for our future self to handle.
Quite often, we don’t handle errors because we genuinely don’t know how the external system will behave and what types of errors to expect from it. Indeed, it can be overwhelming to consider all the possible corner cases and provide appropriate reactions to them. What should I do if the server returns a 503 error? What if I am rate-limited? What if there’s a connection timeout, and so on? It involves a long list of exceptional cases and handlers that need to be implemented, documented, and tested.
Content Preview
When working on external integrations, we often implement basic error handling. Most of the time, we just use
resp.raise_for_status()
and leave it for our future self to handle.
Quite often, we don’t handle errors because we genuinely don’t know how the external system will behave and what types of errors to expect from it. Indeed, it can be overwhelming to consider all the possible corner cases and provide appropriate reactions to them. What should I do if the server returns a 503 error? What if I am rate-limited? What if there’s a connection timeout, and so on? It involves a long list of exceptional cases and handlers that need to be implemented, documented, and tested.
Interface-mock-live (IML) pattern for connecting with third-party services in Python applications
Published: Mon, 08 Jan 2024 00:00:00 +0000
Updated: Mon, 08 Jan 2024 00:00:00 +0000 UTC: 2024-01-08 00:00:00+00:00
URL: https://roman.pt/posts/iml/
To KISS or not to KISS
I remember how, several years ago at Doist, we talked about integrating with external services, like email providers or analytics tools. The question was whether to use a simple function or an abstraction layer.
We ended up having two groups.
KISSers. The first one advocated for following the KISS principle and calling the service API directly. Something as simple as storing an API token in your settings, then calling requests.get() on an endpoint. Wrap this in a function and you’re done.
Content Preview
To KISS or not to KISS
I remember how, several years ago at
Doist
, we talked about integrating with external services, like email providers or analytics tools. The question was whether to use a simple function or an abstraction layer.
We ended up having two groups.
KISSers.
The first one advocated for following the
KISS principle
and calling the service API directly. Something as simple as storing an API token in your settings, then calling
requests.get()
on an endpoint. Wrap this in a function and you’re done.
In update API endpoints that allow for partial updates (aka PATCH updates), we need to know if a model field has been explicitly set by the caller.
Usually, we use None to indicate an unset value. But if None is also a valid value, how can we distinguish between None being explicitly set and None meaning “unset”?
For example, let’s say we have an optional field in the user profile, like a phone number. When using the user profile API endpoint, it’s not clear what to do if the phone number value is None. Should we reset it or keep it as it is?
Content Preview
In update API endpoints that allow for partial updates (aka PATCH updates), we need to know if a model field has been explicitly set by the caller.
Usually, we use None to indicate an unset value. But if None is also a valid value, how can we distinguish between None being explicitly set and None meaning “unset”?
For example, let’s say we have an optional field in the user profile, like a phone number. When using the user profile API endpoint, it’s not clear what to do if the phone number value is None. Should we reset it or keep it as it is?
GitHub Copilot Context
Published: Tue, 19 Dec 2023 00:00:00 +0000
Updated: Tue, 19 Dec 2023 00:00:00 +0000 UTC: 2023-12-19 00:00:00+00:00
URL: https://roman.pt/posts/copilot-context/
How to provide coding guidelines for GitHub Copilot and influence GitHub Copilot suggestions.
In my project, I use naming conventions for models. I have different suffixes for different model types, and I subclass my models from various base classes.
It would be awesome if I could let GitHub Copilot know about my conventions, so it can suggest more accurate code right from the start.
Based on my experience, GitHub Copilot seems to make suggestions by considering the context beyond the current file. The developers of Copilot have confirmed this, although they haven’t explicitly mentioned what exactly is included in this context. Here’s a discussion on this topic: GitHub Copilot Context Discussion.
Content Preview
How to provide coding guidelines for GitHub Copilot and influence GitHub Copilot suggestions.
In my project, I use naming conventions for models. I have different suffixes for different model types, and I subclass my models from various base classes.
It would be awesome if I could let GitHub Copilot know about my conventions, so it can suggest more accurate code right from the start.
Based on my experience, GitHub Copilot seems to make suggestions by considering the context beyond the current file. The developers of Copilot have confirmed this, although they haven’t explicitly mentioned what exactly is included in this context. Here’s a discussion on this topic:
GitHub Copilot Context Discussion
.
Services are a missing layer in the Django architecture. Django does not provide guidance on where to place complex logic for modifying multiple models, but many development teams have chosen to follow the clean architecture pattern and introduce a service layer. This layer acts as a middleman between interfaces such as views or API endpoints, and models.
However, in Django, many features are built around direct use of models. For example, Django admin assumes that models are directly modified and calls the save() method on changes.
Content Preview
Services are a missing layer in the Django architecture. Django does not provide guidance on where to place complex logic for modifying multiple models, but many development teams have chosen to follow the clean architecture pattern and introduce a service layer. This layer acts as a middleman between interfaces such as views or API endpoints, and models.
However, in Django, many features are built around direct use of models. For example, Django admin assumes that models are directly modified and calls the
save()
method on changes.
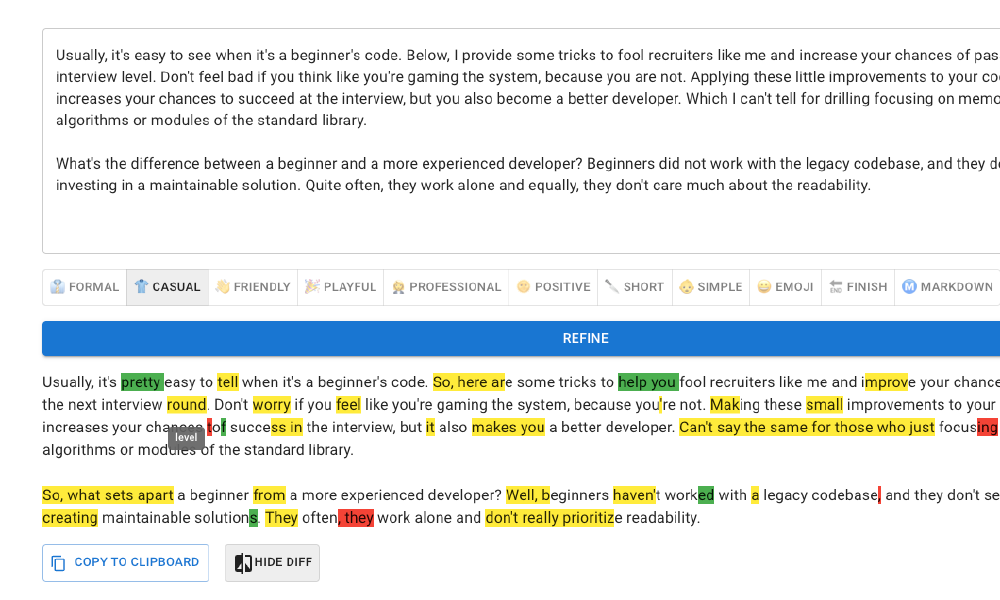
I created a Text Refiner, an open-source project that automatically fixes grammar and stylistic errors. It can also adjust the tone and formatting.
That is addictively useful. Now, pretty much all my git commit messages, comments to Jira tickets, and Slack comments pass through the wisdom of this tool. The post you are reading has also gone through a series of refinements.
How does it help me?
It helps minimize any non-native speaker quirks. Sometimes, I struggle with complex grammatical constructions or end up using expressions that don’t quite exist. I’m sure my English writing has a noticeable Russian accent, even if I can’t hear it. The refiner helps me make my writing sound more natural to native speakers.
Content Preview
I created a
Text Refiner
, an open-source project that automatically fixes grammar and stylistic errors. It can also adjust the tone and formatting.
That is addictively useful. Now, pretty much all my git commit messages, comments to Jira tickets, and Slack comments pass through the wisdom of this tool. The post you are reading has also gone through a series of refinements.
How does it help me?
It helps minimize any non-native speaker quirks. Sometimes, I struggle with complex grammatical constructions or end up using expressions that don’t quite exist. I’m sure my English writing has a noticeable Russian accent, even if I can’t hear it. The refiner helps me make my writing sound more natural to native speakers.
From Django class-based views to service functions
Photo by Valery Fedotov
If you use Django class-based views (CBV), do you feel like it takes significant mental effort to wrap your head around the logic spread across various mixins? I have never been a big fan of Django’s class-based views (CBV) and their mixin approach. In my experience, classical function-based views (FBV) work as well as CBV, but provide more readable code.
What are the problems of class-based views
The logic stops being linear. Instead of running the code sequentially as written, the execution flow jumps between different small functions and classes in seemingly random order. Some classes belong to your code, while others are provided by the framework. Some methods extend methods of superclasses and call super(), forcing you to go down deeper into the rabbit hole. Serving a noble purpose of code de-duplication, class-based views often offer the cure that is worse than the disease. The code gets messy in an attempt to save or reuse a few lines of code.
Content Preview
Photo by
Valery Fedotov
If you use Django class-based views (CBV), do you feel like it takes significant mental effort to wrap your head around the logic spread across various mixins? I have never been a big fan of Django’s class-based views (CBV) and their mixin approach. In my experience, classical function-based views (FBV) work as well as CBV, but provide more readable code.
What are the problems of class-based views
The logic stops being linear
. Instead of running the code sequentially as written, the execution flow jumps between different small functions and classes in seemingly random order. Some classes belong to your code, while others are provided by the framework. Some methods extend methods of superclasses and call
super()
, forcing you to go down deeper into the rabbit hole. Serving a noble purpose of code de-duplication, class-based views often offer the cure that is worse than the disease. The code gets messy in an attempt to save or reuse a few lines of code.
Photo by Markus Winkler
Parametrizing pytest fixtures is a powerful technique for writing more concise and readable tests. I find parametrizing fixtures helpful in two cases.
When testing multiple implementations of the same interface.
When testing the same function against different inputs.
Testing interface implementations
Thanks to Python duck typing, you don’t have to explicitly define interfaces. Any object that has the required attributes and methods can be used as an interface implementation.
Content Preview
Photo by
Markus Winkler
Parametrizing pytest fixtures
is a powerful technique for writing more concise and readable tests. I find parametrizing fixtures helpful in two cases.
When testing multiple implementations of the same interface.
When testing the same function against different inputs.
Testing interface implementations
Thanks to Python duck typing, you don’t have to explicitly define interfaces. Any object that has the required attributes and methods can be used as an interface implementation.
10 Minutes
Published: Tue, 28 Feb 2023 00:00:00 +0000
Updated: Tue, 28 Feb 2023 00:00:00 +0000 UTC: 2023-02-28 00:00:00+00:00
URL: https://roman.pt/posts/10-minutes/
Setting aside ten minutes daily to learn something new is possible. If it is not, where does your time go?
On a personal level: as you wake up, you have roughly 100 such 10-minute blocks before you go to bed. Can you squeeze out one block before bed, while commuting, or after lunch?
On a company level: your company is buying roughly 50 10-minute blocks per day from its employees. Investing one of those fifty blocks in learning doesn’t make a difference for day-to-day work but sets the foundation for the individual growth of your team members.
Content Preview
Setting aside ten minutes daily to learn something new is possible. If it is not, where does your time go?
On a personal level:
as you wake up, you have roughly 100 such 10-minute blocks before you go to bed. Can you squeeze out one block before bed, while commuting, or after lunch?
On a company level:
your company is buying roughly 50 10-minute blocks per day from its employees. Investing one of those fifty blocks in learning doesn’t make a difference for day-to-day work but sets the foundation for the individual growth of your team members.
When choosing between alternatives, whether big or small, it’s way too easy to fall into an analysis paralysis trap.
Quite often, I find myself indecisive when I make a non-trivial purchase or a decision that will likely determine my future. In other words, not like choosing between types of cheese in a supermarket, but rather choosing which apartment to rent, which school to choose for my kids, which country to live in, which framework to use for my next side-project, etc.
Content Preview
When choosing between alternatives, whether big or small, it’s way too easy to fall into an analysis paralysis trap.
Quite often, I find myself indecisive when I make a non-trivial purchase or a decision that will likely determine my future. In other words, not like choosing between types of cheese in a supermarket, but rather choosing which apartment to rent, which school to choose for my kids, which country to live in, which framework to use for my next side-project, etc.
Photo by Artem Bryzgalov
If it hurts, do it more often
In the summer of last year, I joined Building Radar as a contractor developer. The team recently launched a new product, onboarded some clients, and was looking for ways to move forward faster.
When I joined, the team was releasing a new product version every three weeks, and the release process was somewhat painful. Things fell apart when deployed to production, migrations took longer than anticipated, features didn’t work quite as advertised, etc.
Content Preview
Photo by
Artem Bryzgalov
If it hurts, do it more often
In the summer of last year, I joined
Building Radar
as a contractor developer. The team recently launched a new product, onboarded some clients, and was looking for ways to move forward faster.
When I joined, the team was releasing a new product version every three weeks, and the release process was somewhat painful. Things fell apart when deployed to production, migrations took longer than anticipated, features didn’t work quite as advertised, etc.
There is a 2009 post from Derek Sivers, No yes. Either HELL YEAH! or no, a very short one, and it can be condensed even further into a single sentence.
If you’re not saying “HELL YEAH!” about something, say no.
Brilliant advice on learning to say “no” to so-so experiences to laser-focus on a single stellar thing.
Yet, there is a big caveat! HELL YEAH doesn’t guarantee you make the best choice out of the outcomes. It just helps you make the choice you are most excited about right now. And it’s not the same thing.
Content Preview
There is a 2009 post from Derek Sivers,
No yes. Either HELL YEAH! or no
, a very short one, and it can be condensed even further into a single sentence.
If you’re not saying “HELL YEAH!” about something, say no.
Brilliant advice on learning to say “no” to so-so experiences to laser-focus on a single stellar thing.
Yet, there is a big caveat! HELL YEAH doesn’t guarantee you make the best choice out of the outcomes. It just helps you make the choice you are most excited about right now. And it’s not the same thing.
7 habit-building techniques I learned from 'Atomic Habits'
Published: Tue, 24 Jan 2023 00:00:00 +0000
Updated: Tue, 24 Jan 2023 00:00:00 +0000 UTC: 2023-01-24 00:00:00+00:00
URL: https://roman.pt/posts/atomic-habits/
It’s been a little over a year since I read Atomic Habits and I wanted to share some of the key takeaways that have really resonated with me. When I first read the book, I thought it was an enjoyable read, but it didn’t necessarily blow my mind. It wasn’t until I started implementing some of the concepts from the book that I had my “a-ha” moment.
Here are a few things that I’ve taken from the book and how they’ve helped me:
Content Preview
It’s been a little over a year since I read
Atomic Habits
and I wanted to share some of the key takeaways that have really resonated with me. When I first read the book, I thought it was an enjoyable read, but it didn’t necessarily blow my mind. It wasn’t until I started implementing some of the concepts from the book that I had my “a-ha” moment.
Here are a few things that I’ve taken from the book and how they’ve helped me:
Simplifying PostgreSQL enum migrations with SQLAlchemy and alembic-enums
Published: Tue, 17 Jan 2023 00:00:00 +0000
Updated: Tue, 17 Jan 2023 00:00:00 +0000 UTC: 2023-01-17 00:00:00+00:00
URL: https://roman.pt/posts/alembic-enums/
Do you really need PostgreSQL enums? (Update from 9 Jan 2024)
Working with Django reminds me how much less painful enums could be if they were represented by VARCHAR fields at the database level and enforced by Django models at the application level.
Inspired by this, in my next SQLAlchemy model, I used the ChoiceType from the sqlalchemy-utils package. Actually, I combined it with Tiangolo’s SQLModel, and the development experience was quite nice.
Content Preview
Do you really need PostgreSQL enums? (Update from 9 Jan 2024)
Working with Django reminds me how much less painful enums could be if they were represented by VARCHAR fields at the database level and enforced by Django models at the application level.
Inspired by this, in my next SQLAlchemy model, I used the ChoiceType from the
sqlalchemy-utils
package. Actually, I combined it with Tiangolo’s SQLModel, and the development experience was quite nice.
What I Wrote About in 2022
In 2022, I wrote 20 blog posts starting with Dealing with large pull requests and closing the year with Stop Me Before It’s Too Late.
Additionally, I tried to record my TIL findings in May and June, but quickly abandoned this idea after only three posts, still trying to determine if the format made sense.
The topics of my blog posts ranged from niche technical subjects like Parse JSON-encoded query strings in FastAPI, to thoughts on management and teamwork like Be kind to your manager, to classic rants like AWS Surprise Bill and musings on society and the dark sides of human nature in 1984 is now.
Content Preview
Additionally, I tried to record my TIL findings in May and June, but quickly abandoned this idea after only three posts, still trying to determine if the format made sense.
The New Year celebration is tough for me. One thing that makes it especially challenging is that the tradition requires you to be awake enough to observe the second 00:00:01 of the upcoming year and enthusiastically cheer its arrival.
Throughout the years, I’ve learned that while I can be awake, there is never enough energy to be enthusiastic about the event. Starting at around 10 PM, I get more tired and grumpier with every minute. I talk less, and my remarks usually become more caustic and socially inappropriate when I do open my mouth.
Content Preview
The New Year celebration is tough for me. One thing that makes it especially challenging is that the tradition requires you to be awake enough to observe the second 00:00:01 of the upcoming year and enthusiastically cheer its arrival.
Throughout the years, I’ve learned that while I can be awake, there is never enough energy to be enthusiastic about the event. Starting at around 10 PM, I get more tired and grumpier with every minute. I talk less, and my remarks usually become more caustic and socially inappropriate when I do open my mouth.
Proactivity and communication are essential for healthy relationships at work. I often use the phrase “Stop me before it’s too late” in my work style and find that it can serve as a good catchphrase marker for these two traits.
The context of saying “stop me before it’s too late” is typically when I encounter a problem (usually a blocker) with a non-trivial solution, and I’m about to fix it using my best judgment. Before starting, I communicate the problem and my proposed solution in writing and invite feedback from my colleagues. I give them the opportunity to stop me before it’s too late.
Content Preview
Proactivity and communication are essential for healthy relationships at work. I often use the phrase “Stop me before it’s too late” in my work style and find that it can serve as a good catchphrase marker for these two traits.
The context of saying “stop me before it’s too late” is typically when I encounter a problem (usually a blocker) with a non-trivial solution, and I’m about to fix it using my best judgment. Before starting, I communicate the problem and my proposed solution in writing and invite feedback from my colleagues. I give them the opportunity to stop me before it’s too late.
Data structures evolve with time. Say you have data storage with person objects.
I assume the storage is schema-less. Maybe it’s your primary storage in MongoDB, a Redis cache, or a log record in ElasticSearch.
{
"name": "Guido Van Rossum",
"email": "guido@python.org"
}
At some point, you decide to store a profession alongside each person. New records can look like this.
{
"name": "Ryan Dahl",
"email": "ryan@nodejs.com",
"profession": "Software developer"
}
Old objects stored in the database before the migration don’t have a “profession” attribute. If your code expects every person to have a defined profession field, it will crash the first time it interacts with the old data.
Content Preview
Data structures evolve with time. Say you have data storage with person objects.
I assume the storage is schema-less. Maybe it’s your primary storage in MongoDB, a Redis cache, or a log record in ElasticSearch.
{
"name": "Guido Van Rossum",
"email": "guido@python.org"}
At some point, you decide to store a profession alongside each person. New records can look like this.
Old objects stored in the database before the migration don’t have a “profession” attribute. If your code expects every person to have a defined profession field, it will crash the first time it interacts with the old data.
You write a specification draft and share it with colleagues for feedback.
With Google Docs, Notion, or Confluence, typically, colleagues leave contextual feedback on specific lines of the document. From there, an entire discussion can evolve.
A specification with many unresolved comments is a time sink for everyone who touches it. Not only do they need to read the spec, they also need to follow all the threads and discussions and find the final opinion. It’s not uncommon for some of them to hang without a resolution, leaving it to whoever made the implementation.
Content Preview
You write a specification draft and share it with colleagues for feedback.
With Google Docs, Notion, or Confluence, typically, colleagues leave contextual feedback on specific lines of the document. From there, an entire discussion can evolve.
A specification with many unresolved comments is a time sink for everyone who touches it. Not only do they need to read the spec, they also need to follow all the threads and discussions and find the final opinion. It’s not uncommon for some of them to hang without a resolution, leaving it to whoever made the implementation.
Martin Fowler argues that functions should be as short as a few lines of code. I feel like that’s a bit extreme, and usually, my functions are longer than that.
It turns out my test functions are a different beast. Reflecting on how I write code, I noticed that my test functions are usually much shorter than my regular code. Not only are they shorter, but in general, they look different.
Content Preview
Martin Fowler
argues
that functions should be as short as a few lines of code. I feel like that’s a bit extreme, and usually, my functions are longer than that.
It turns out my test functions are a different beast. Reflecting on how I write code, I noticed that my test functions are usually much shorter than my regular code. Not only are they shorter, but in general, they look different.
I passed the AWS Certified Developer - Associate certification exam a week ago. Below I’m sharing my journey, thoughts, and tips about the process.
Why did I decide to pass the certification exam?
In broad strokes, I had two primary goals: the certificate and the knowledge that the preparation brings.
Knowledge part. I worked with AWS for many years and felt I understood the ecosystem well enough. Still, I always had a feeling that my knowledge was quite chaotic and, likely, incomplete. I wanted to have a more systematic approach to learning about the platform.
Content Preview
I passed the AWS Certified Developer - Associate certification exam a week ago. Below I’m sharing my journey, thoughts, and tips about the process.
Why did I decide to pass the certification exam?
In broad strokes, I had two primary goals: the certificate and the knowledge that the preparation brings.
Knowledge part.
I worked with AWS for many years and felt I understood the ecosystem well enough. Still, I always had a feeling that my knowledge was quite chaotic and, likely, incomplete. I wanted to have a more systematic approach to learning about the platform.
You know developers solve business problems with code. Taking this literally, you are so busy working on new features that you often find yourself taking implementation shortcuts. Under the pressure of the product team, you don’t have time to go back and clean it up.
You know, in the long run, this is not sustainable. Code shortcuts inevitably make product quality degrade. Still, while evident in hindsight, the idea is hard to sell to product folks.
Content Preview
You know developers solve business problems with code. Taking this literally, you are so busy working on new features that you often find yourself taking implementation shortcuts. Under the pressure of the product team, you don’t have time to go back and clean it up.
You know, in the long run, this is not sustainable. Code shortcuts inevitably make product quality degrade. Still, while evident in hindsight, the idea is hard to sell to product folks.
Performance profiling in Python
When it comes to performance, you never know where the bottleneck is. Fortunately, the Python ecosystem has tools to eliminate guesswork. They are easy to learn and don’t require codebase instrumentation or preparatory work.
When I worked at Doist, I spent hours staring at the profiling plots of our full sync API. In Todoist API, full sync is the first command called after a login. In our battle for a smooth experience, we went to great lengths to optimize the first load.
Content Preview
Performance profiling in Python
When it comes to performance, you never know where the bottleneck is. Fortunately, the Python ecosystem has tools to eliminate guesswork. They are easy to learn and don’t require codebase instrumentation or preparatory work.
When I worked at Doist, I spent hours staring at the profiling plots of our full sync API. In
Todoist API
, full sync is the first command called after a login. In our battle for a smooth experience, we went to great lengths to optimize the first load.
I started my new project with the AWS SAM framework. In this post, I share some takeaways I have learned about creating serverless applications with it.
Learning curve
Overall, it’s a different experience from writing a web app built around a classical monolith web framework. If you look at speakers presenting AWS SAM on stage, you may feel that it’s an excellent choice for a quick prototype or an API endpoint that you can start and finish within a few hours. In reality, if you don’t have much experience building cloud-native applications, there is a lot to learn, mostly with trial and error.
Content Preview
I started my new project with the
AWS SAM framework
. In this post, I share some takeaways I have learned about creating serverless applications with it.
Learning curve
Overall, it’s a different experience from writing a web app built around a classical monolith web framework. If you look at speakers presenting AWS SAM on stage, you may feel that it’s an excellent choice for a quick prototype or an API endpoint that you can start and finish within a few hours. In reality, if you don’t have much experience building cloud-native applications, there is a lot to learn, mostly with trial and error.
A memo about my setup for a TypeScript React project: I copy and paste these commands whenever I need to start a new project and ensure that it has all linters, formatters, and pre-commit hooks configured.
Initialize proper version
I use nvm, and I automatically initialize the node environment with nvm if .nvmrc is found.
# File ~/.zshrc
test -f ./.nvmrc && nvm use
Start a new project
I tried Vite for a few recent projects and liked it. That’s how I create a new empty project.
Content Preview
A memo about my setup for a TypeScript React project: I copy and paste these commands whenever I need to start a new project and ensure that it has all linters, formatters, and pre-commit hooks configured.
Initialize proper version
I use
nvm
, and I automatically initialize the node environment with nvm if
.nvmrc
is found.
# File ~/.zshrctest -f ./.nvmrc && nvm use
Start a new project
I tried
Vite
for a few recent projects and liked it. That’s how I create a new empty project.
GitHub Copilot
Published: Tue, 28 Jun 2022 00:00:00 +0000
Updated: Tue, 28 Jun 2022 00:00:00 +0000 UTC: 2022-06-28 00:00:00+00:00
URL: https://roman.pt/posts/github-copilot/
$100 per year for GitHub Copilot is a no-brainer investment. The expectations from a tool that writes code are as inflated as programmers’ salaries and egos, but Copilot delivers on them. It helps me switch contexts less often and stay in the flow. It saves my mental energy by writing boilerplate code, helping me come up with consistent variable names, and writing complete documentation.
Conservatively, even if it saves me five minutes daily, it’s still a good investment. Realistically, the amount of saved time can get up to an hour on a good day.
Content Preview
$100 per year for GitHub Copilot is a no-brainer investment. The expectations from a tool that writes code are as inflated as programmers’ salaries and egos, but Copilot delivers on them. It helps me switch contexts less often and stay in the flow. It saves my mental energy by writing boilerplate code, helping me come up with consistent variable names, and writing complete documentation.
Conservatively, even if it saves me five minutes daily, it’s still a good investment. Realistically, the amount of saved time can get up to an hour on a good day.
Photo by Elisa Ventur
I started my career as a developer, then spent several years as a team lead, and then got back to mostly writing code again. Here, I’m reflecting on the challenges of being a middle manager.
Everything is more complicated than it looks.
Why is my manager so stressed?
They may not know how to manage yet
All the time, brilliant individual contributors get promoted to team leads only to learn that it’s a job requiring a completely different skill set.
Content Preview
Photo by
Elisa Ventur
I started my career as a developer, then spent several years as a team lead, and then got back to mostly writing code again. Here, I’m reflecting on the challenges of being a middle manager.
Everything is more complicated than it looks.
Why is my manager so stressed?
They may not know how to manage yet
All the time, brilliant individual contributors get promoted to team leads only to learn that it’s a job requiring a completely different skill set.
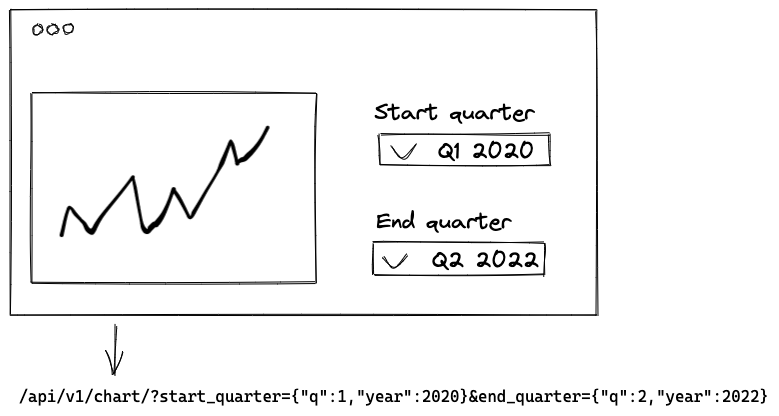
React ↔︎ FastAPI dashboard
I work on a dashboard that shows charts with filters.
React serializes filter parameters into JSON and sends them to FastAPI in a query string.
The FastAPI server returns the data to display the chart.
My dashboard
FastAPI parses your request and maps it to controller parameters. Can I turn complex parameters in the query string into Pydantic models?
class Quarter(BaseModel):
q: int
year: int
@app.get("/api/v1/chart")
def get_chart(
start_quarter: Quarter = parse_querystring_and_create_quarter_instance_somehow(),
end_quarter: Quarter = parse_querystring_and_create_quarter_instance_somehow(),
):
...
FastAPI request mapping
FastAPI automatically maps query strings to scalar function parameters. We get strings inside the functions.
Content Preview
React ↔︎ FastAPI dashboard
I work on a dashboard that shows charts with filters.
React serializes filter parameters into JSON and sends them to FastAPI in a query string.
The FastAPI server returns the data to display the chart.
My dashboard
FastAPI parses your request and maps it to controller parameters. Can I turn complex parameters in the query string into Pydantic models?
Stray service
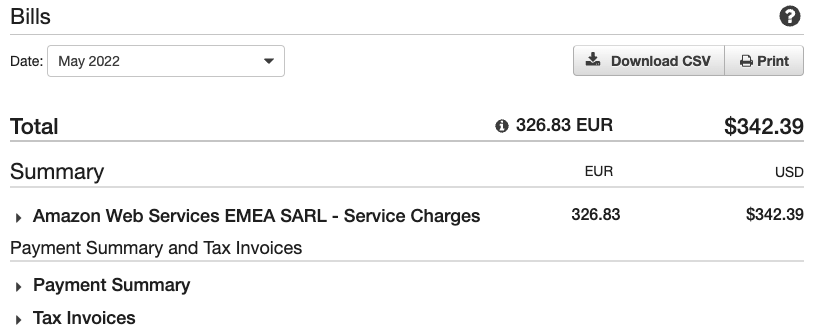
I got a surprise bill from AWS. More than $300 for May and almost $100 for June. Until then, I thought that surprise bills were something that happened to others.
My surprise bill from AWS
About a month ago, I completed the Amazon MQ workshop. I was sure that I destroyed all the services when I completed it. It turns out that was not the case. The CloudFormation template failed to delete the Amazon MQ broker, and I overlooked that error.
Content Preview
Stray service
I got a surprise bill from AWS. More than $300 for May and almost $100 for June. Until then, I thought that surprise bills were something that happened to others.
My surprise bill from AWS
About a month ago, I completed the
Amazon MQ workshop
. I was sure that I destroyed all the services when I completed it. It turns out that was not the case. The CloudFormation template failed to delete the Amazon MQ broker, and I overlooked that error.
State of JS 2021
Published: Wed, 01 Jun 2022 00:00:00 +0000
Updated: Wed, 01 Jun 2022 00:00:00 +0000 UTC: 2022-06-01 00:00:00+00:00
URL: https://roman.pt/til/2022-06-01/
I came across the state of JavaScript 2021 report, released in February. The report falls into the same bucket as the Python Developer Survey and StackOverflow developer survey, but with focus on the JavaScript ecosystem.
Content Preview
Many features of modern JavaScript are not known to me. As someone who considers himself “good enough” in JavaScript, I find it both exciting and uncomfortable: oh, the number of things I still don’t know is enormous.
It was interesting to look at the top list of the frameworks. With React as the most popular,
Svelte
as something people want to learn, and
Solid
(never heard of it) which brings the most satisfaction.
Vite
, a better webpack, is on the top list of interest and satisfaction. This observation matches my experience. I started my new project with Vite, React, and TypeScript (
yarn create vite --template react-ts
), and I can confirm that it does everything necessary out of the box, and so far, I have never had any problems with it.
I liked the “Resources” review that features blogs, podcasts, and people to follow in the JavaScript community.
Published: Fri, 27 May 2022 00:00:00 +0000
Updated: Fri, 27 May 2022 00:00:00 +0000 UTC: 2022-05-27 00:00:00+00:00
URL: https://roman.pt/til/2022-05-27/
LSI shares partitions with the data and has the same partition key but a different key. Of limited use.
Content Preview
How it works
Data is stored in tables with items like rows.
Rows in tables are uniquely identified by their primary key, consisting of a partition key and an optional sort key.
The schema is not defined for the rest of the attributes. Different items can have different attributes or different types of the same attribute.
Sharding is automated by the hash of the partition key.
Data consistency
Eventual consistency is the default behavior. Strong consistency is an option. Strongly consistent reads are more expensive (2x), and sometimes they may not be available.
Advice: try to design around eventual consistency.
Throughput
Measured in RCU (read capacity units) and WCU (write capacity units)
1 RCU - one strongly or two eventually consistent reads per second (at most 4kb)
1 WCU - one standard write per second (at most 1kb)
Tables are created with the minimal provisioned capacity of 1 RCU and 1 WCU, which costs around $0.59 per month. Can scale up to 10 RCU or 10 WCU.
Throttling on exceeding.
Querying data
Scan. Sort of like
SCAN
in Redis. Iterates over all the records in the table and returns only the ones matching the criteria. Avoid this.
Query. Specify the partition and the sort key expression. It’s cheaper and faster.
Local secondary indexes (LSI)
LSI shares partitions with the data and has the same partition key but a different key. Of limited use.
1984 is now
Published: Mon, 16 May 2022 14:46:21 +0100
Updated: Mon, 16 May 2022 14:46:21 +0100 UTC: 2022-05-16 13:46:21+00:00
URL: https://roman.pt/posts/1984/
Photo by Markus Spiske
I could never expect to read an anti-utopia not as a grim overview of the future but as an outline of today’s world.
I was reading this to reflect on the current events in Russia and thinking about why so many people fell victim to relatively unsophisticated propaganda and became its supporters and apologists.
My biggest takeaway is how amazingly adaptive the human mind is. People can go to great lengths to deny the most apparent facts to protect their safety and comfort.
Content Preview
Photo by
Markus Spiske
I could never expect to read an anti-utopia not as a grim overview of the future but as an outline of today’s world.
I was reading this to reflect on the current events in Russia and thinking about why so many people fell victim to relatively unsophisticated propaganda and became its supporters and apologists.
My biggest takeaway is how amazingly adaptive the human mind is. People can go to great lengths to deny the most apparent facts to protect their safety and comfort.
Elastic Beanstalk
Published: Wed, 11 May 2022 00:00:00 +0000
Updated: Wed, 11 May 2022 00:00:00 +0000 UTC: 2022-05-11 00:00:00+00:00
URL: https://roman.pt/til/2022-05-11/
Played with Elastic Beanstalk.
At first glance, it looks like a very user-unfriendly version of Heroku.
At a second glance, better than it seems. They offer out-of-the-box autoscaling, monitoring, spot instances, and even a wrapper around SQS for queues. The admin panel is quite user-friendly by AWS standards.
In general, of course, everything smells antiquity. There have been no notable updates lately. The latest version of python is 3.8.
In 2011 when they announced it, it could have become a hit, but it didn’t because there were no RDS at the time. When RDS came in, the platform seemed to be of no use to anyone.
Content Preview
At first glance, it looks like a very user-unfriendly version of Heroku.
At a second glance, better than it seems. They offer out-of-the-box autoscaling, monitoring, spot instances, and even a wrapper around SQS for queues. The admin panel is quite user-friendly by AWS standards.
In general, of course, everything smells antiquity. There have been no notable updates lately. The latest version of python is 3.8.
In 2011 when they announced it, it could have become a hit, but it didn’t because there were no RDS at the time. When RDS came in, the platform seemed to be of no use to anyone.
I released Django Plausible Proxy, a Django application to proxy requests and send server-side events to Plausible Analytics.
Plausible is a lightweight and open-source web analytics platform, a privacy-friendly alternative to Google Analytics. I started using it for Django side projects about a month ago and loved its minimalistic interface and “exactly what I need” type of reports.
Initially, the integration code lived inside the project, but as it grew in functionality, I extracted it into a separate package that is available on PyPI and GitHub.
Content Preview
Plausible is a lightweight and open-source web analytics platform, a privacy-friendly alternative to Google Analytics. I started using it for Django side projects about a month ago and loved its minimalistic interface and “exactly what I need” type of reports.
Initially, the integration code lived inside the project, but as it grew in functionality, I extracted it into a separate package that is available on
PyPI
and
GitHub
.
In software development, we often make decisions that look like an excellent idea in the short run but result in the horror of maintenance down the road.
Letting two independent services use a shared database is one of those ideas.
More often, I’ve seen a less obvious variant. There’s a legacy system that’s hard to maintain. When the business needs new functionality quickly, they recruit new developers to create a better service from scratch. To use the legacy system data, the development team explores existing data structures and connects their new code to the old database.
Content Preview
In software development, we often make decisions that look like an excellent idea in the short run but result in the horror of maintenance down the road.
Letting two independent services use a shared database is one of those ideas.
More often, I’ve seen a less obvious variant. There’s a legacy system that’s hard to maintain. When the business needs new functionality quickly, they recruit new developers to create a better service from scratch. To use the legacy system data, the development team explores existing data structures and connects their new code to the old database.
Photo by Jess Zoerb
Repaying your tech debt with a code cleanup hackathon? Planning a bug fixing week to decrease the issues backlog? Likely, you’re wasting your time.
When I worked at Doist, we had a long-standing issue with Sentry. Sentry is an error tracking service, and our application recorded every exception there. Quickly, the list of issues grew so deep that our team learned to disregard its alerts.
Content Preview
Photo by
Jess Zoerb
Repaying your tech debt with a code cleanup hackathon? Planning a bug fixing week to decrease the issues backlog? Likely, you’re wasting your time.
When I worked at Doist, we had a long-standing issue with Sentry. Sentry is an error tracking service, and our application recorded every exception there. Quickly, the list of issues grew so deep that our team learned to disregard its alerts.
In a post Don’t let dicts spoil your code I wrote that it’s better to avoid raw data structures such as dicts and lists. Instead, I suggest converting them as soon as possible to objects representing your domain.
In a few places in my code, I found that raw dicts appear as attributes of SQLAlchemy models’ JSON fields. It feels dirty: you have a well-defined model with a field storing unstructured data.
Content Preview
In a post
Don’t let dicts spoil your code
I wrote that it’s better to avoid raw data structures such as dicts and lists. Instead, I suggest converting them as soon as possible to objects representing your domain.
In a few places in my code, I found that raw dicts appear as attributes of SQLAlchemy models’ JSON fields. It feels dirty: you have a well-defined model with a field storing unstructured data.
Photo by Elise Coates
Sometimes, my pull requests grow too big to review. I want to split them into small chunks to be reviewed and merged independently. At the same time, I want to keep working on the feature in a branch, creating newer pull requests until the work is done.
Automating PR stacks
GitHub has a stacked pull requests feature. For two PRs, you can define their base to say “I want to merge PR 2 into PR 1. I want to merge PR 1 into the main branch.” This is helpful when you work on a large code change, but want to review and merge it in independent smaller chunks. Managing these stacks of PRs is tedious, though.
Content Preview
Photo by
Elise Coates
Sometimes, my pull requests grow too big to review. I want to split them into small chunks to be reviewed and merged independently. At the same time, I want to keep working on the feature in a branch, creating newer pull requests until the work is done.
Automating PR stacks
GitHub has a stacked pull requests feature. For two PRs, you can define their base to say “I want to merge PR 2 into PR 1. I want to merge PR 1 into the main branch.” This is helpful when you work on a large code change, but want to review and merge it in independent smaller chunks. Managing these stacks of PRs is tedious, though.
Photo by Jon Cartagena
Does your pip install -r requirements.txt take ages to install? Make sure you install all binary packages from wheels.
When “pip install” can’t find a wheel, it falls back to installing from source. In a large project, dependency after dependency, it slows down builds and makes developers unhappy.
What are Python wheels and why are they so fast
Long ago, most Python packages were distributed as source code with .tar.gz. The installer downloaded the archive and ran the setup.py script inside it. This format is known as “sdist”, source distribution.
Content Preview
Photo by
Jon Cartagena
Does your
pip install -r requirements.txt
take ages to install? Make sure you install all binary packages from wheels.
When “pip install” can’t find a wheel, it falls back to installing from source. In a large project, dependency after dependency, it slows down builds and makes developers unhappy.
What are Python wheels and why are they so fast
Long ago, most Python packages were distributed as source code with
.tar.gz
. The installer downloaded the archive and ran the
setup.py
script inside it. This format is known as “sdist”, source distribution.
Often, I find myself experimenting in the Django console with ad-hoc model queries.
When it’s not clear how Django turns a queryset into SQL, I find it helpful to print the resulting query. Django QuerySet object has a query attribute. However, its format would benefit from extra formatting.
I used pygments and sqlparse to make the output of query more developer-friendly.
pip install pygments sqlparse
The snippet itself is very straightforward.
# file sql_utils/utils.py
from pygments import highlight
from pygments.formatters import TerminalFormatter
from pygments.lexers import PostgresLexer
from sqlparse import format
from django.db.models import QuerySet
def print_sql(queryset: QuerySet):
formatted = format(str(queryset.query), reindent=True)
print(highlight(formatted, PostgresLexer(), TerminalFormatter()))
This is how it looks in the screenshot.
Content Preview
Often, I find myself experimenting in the Django console with ad-hoc model queries.
When it’s not clear how Django turns a queryset into SQL, I find it helpful to print the resulting query. Django
QuerySet
object has a
query
attribute. However, its format would benefit from extra formatting.
I used
pygments
and
sqlparse
to make the output of
query
more developer-friendly.
Published: Fri, 10 Dec 2021 00:00:00 +0000
Updated: Fri, 10 Dec 2021 00:00:00 +0000 UTC: 2021-12-10 00:00:00+00:00
URL: https://roman.pt/posts/user-stories/
Photo by AbsolutVision
My wake up call
I should admit that all my life, I believed that user stories are feature requests with a fancy and rigid ticket structure. My personal experience is limited.
Last week, I had to explain the concept of user stories to a different person, only to learn that I knew nothing about the subject and mostly cargo-culted them. It’s time to fill the gap. Below I’m sharing my understanding of user stories and notes that I extracted from different sources in the context of a small team or a personal project.
Content Preview
Photo by
AbsolutVision
My wake up call
I should admit that all my life, I believed that user stories are feature requests with a fancy and rigid ticket structure. My personal experience is limited.
Last week, I had to explain the concept of user stories to a different person, only to learn that I knew nothing about the subject and mostly cargo-culted them. It’s time to fill the gap. Below I’m sharing my understanding of user stories and notes that I extracted from different sources in the context of a small team or a personal project.
You can run the script with IPython interactive mode.
$ ipython -i playground.py
...In [1]: session.add(User(name="foo"))
In [2]: session.commit()
SQLAlchemy pitfalls
Columns are nullable by default
The default value of SQLAlchemy
nullable
is True unless it’s a primary key. A foreign key is also nullable by default. If you came from the Django ORM, where the default values for fields are
null=False, blank=False
, you might accidentally create table definitions with nullable fields, which bites you in the future.
Codemaps Leaflet
Published: Tue, 09 Nov 2021 11:23:17 +0000
Updated: Tue, 09 Nov 2021 11:23:17 +0000 UTC: 2021-11-09 11:23:17+00:00
URL: https://roman.pt/posts/codemaps-leaflet/
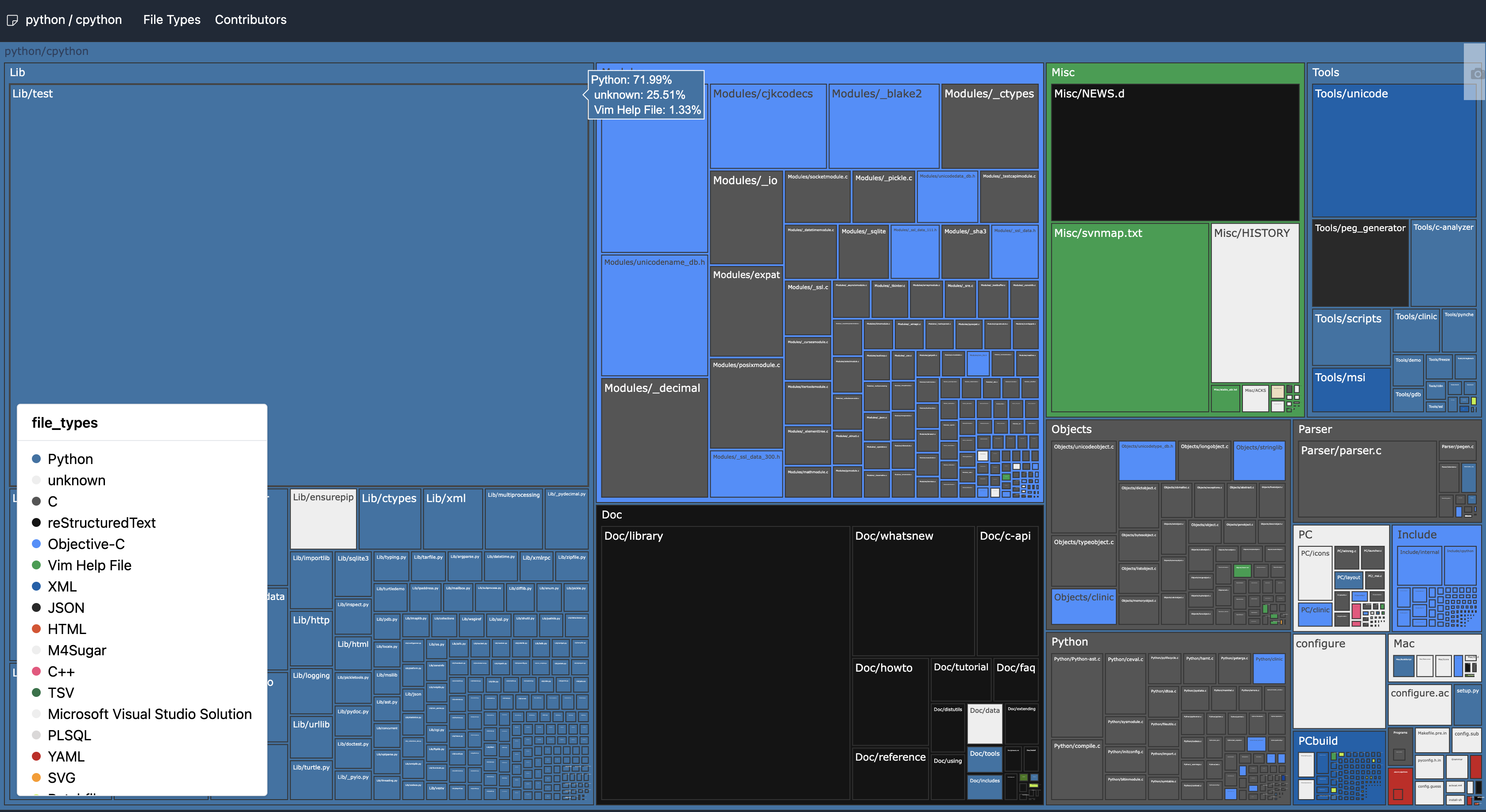
Codemaps is my project to visualize git repos content using the treemaps visualization technique, available at https://usecodemaps.com/.
Codemaps of CPython repo
At the moment, it uses plotly treemaps and React Plotly.js to display the maps. I liked how it worked, but I didn’t appreciate how sluggish it was on large repositories. Besides, plotly didn’t let me tweak the visualization part as much as I wanted.
I thought it would be nice to reuse a JavaScript library that shows geographic maps to show the codemaps. The functionality overlap should be enough for me to climb onto their shoulders and take advantage of their out-of-the-box zoom and scale functionality, top-notch performance, etc.
Content Preview
Codemaps is my project to visualize git repos content using the treemaps visualization technique, available at
https://usecodemaps.com/
.
Codemaps of CPython repo
At the moment, it uses
plotly treemaps
and
React Plotly.js
to display the maps. I liked how it worked, but I didn’t appreciate how sluggish it was on large repositories. Besides, plotly didn’t let me tweak the visualization part as much as I wanted.
I thought it would be nice to reuse a JavaScript library that shows geographic maps to show the codemaps. The functionality overlap should be enough for me to climb onto their shoulders and take advantage of their out-of-the-box zoom and scale functionality, top-notch performance, etc.
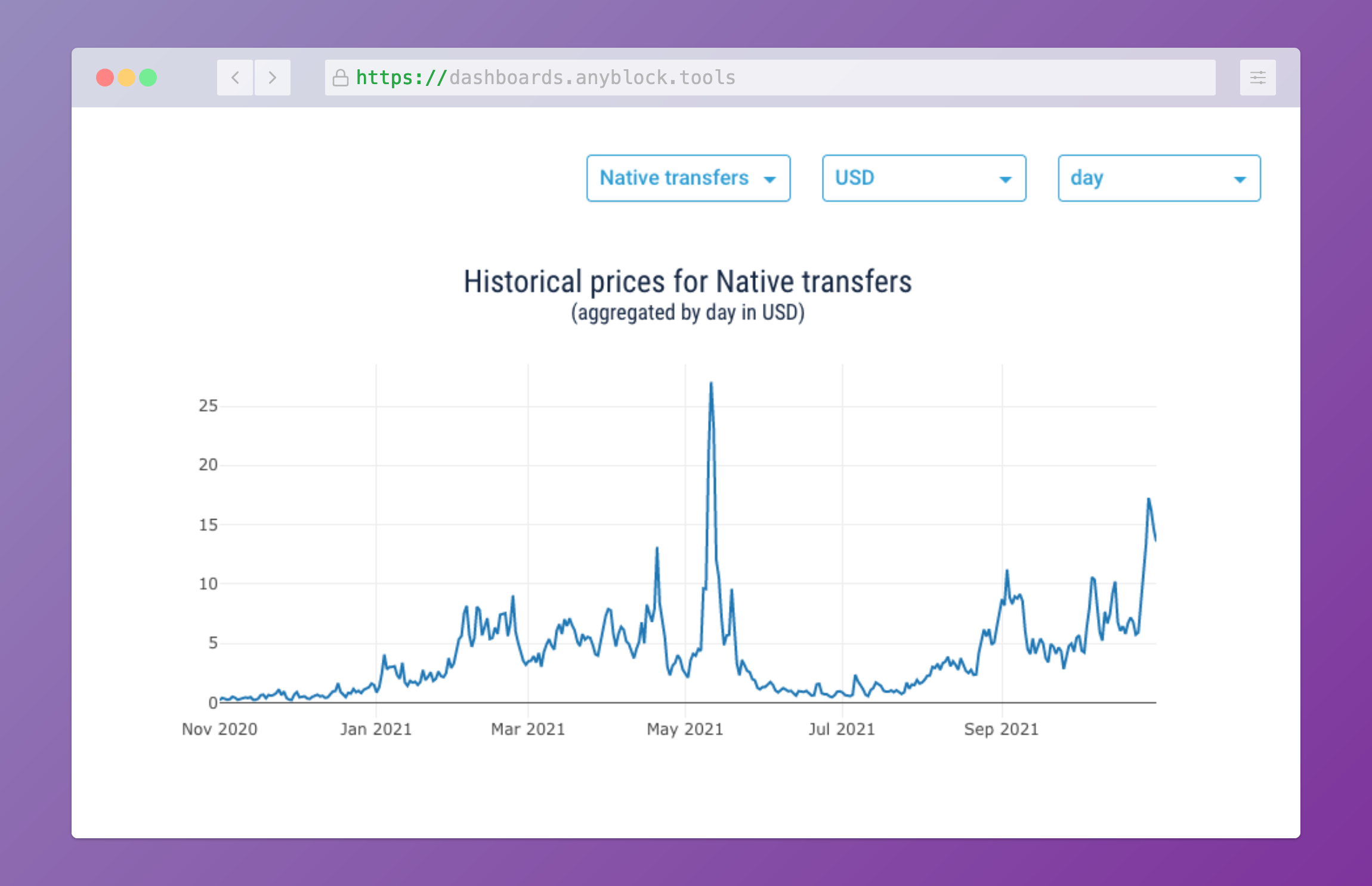
Time series plot for historical pricing of Ethereum transfers
Some takeaways on practical time series caching with Python and Redis from the Dashboards project that I implemented with Anyblock Analytics in 2021. The full code of the sample project is available at github.com/imankulov/time-series-caching.
TLDR. We replaced a generic Flask-caching solution with caching by date buckets, and I liked it.
I like it so much that I decided to write a blog post, sharing how we came to the solution. More specifically:
Content Preview
Time series plot for historical pricing of Ethereum transfers
TLDR. We replaced a generic Flask-caching solution with caching by date buckets, and I liked it
.
I like it so much that I decided to write a blog post, sharing how we came to the solution. More specifically:
Flow: The Psychology of Optimal Experience
Published: Fri, 22 Oct 2021 10:11:00 +0100
Updated: Fri, 22 Oct 2021 10:11:00 +0100 UTC: 2021-10-22 09:11:00+00:00
URL: https://roman.pt/posts/flow-book/
Key idea: our happiness can depend more on our state of mind than on external factors.
Almost any activity can become a source of happiness if you dive deep enough. The key is to find an activity that you can easily turn into a game and start enjoying the process of learning and self-improvement rather than waiting for the outcome. Google “8 elements of Flow.”
The book is worth starting but not necessarily finishing. I abandoned it about halfway through when I became annoyed with the pattern “you can find enjoyment doing X, here’s how” for different X.
Content Preview
Key idea: our happiness can depend more on our state of mind than on external factors.
Almost any activity can become a source of happiness if you dive deep enough. The key is to find an activity that you can easily turn into a game and start enjoying the process of learning and self-improvement rather than waiting for the outcome. Google “8 elements of Flow.”
The book is worth starting but not necessarily finishing. I abandoned it about halfway through when I became annoyed with the pattern “you can find enjoyment doing X, here’s how” for different X.
Structure Flask Project With Convention Over Configuration
Photo by Simone Viani
When people ask me what a beginner Python developer should choose, Flask or Django, to start their new web project, all other things being equal, I always recommend Django.
Unlike Flask, Django is opinionated. In other words, every time you need to make a choice in Flask, Django has the answer for you. Among others, Django outlines the practical project structure out of the box.
Content Preview
Photo by
Simone Viani
When people ask me what a beginner Python developer should choose, Flask or Django, to start their new web project, all other things being equal, I always recommend Django.
Unlike Flask, Django is opinionated. In other words, every time you need to make a choice in Flask, Django has the answer for you. Among others, Django outlines the practical project structure out of the box.
Photo by Aaron Burden
Overview of tools and services to document your Python web application from installation instructions to public API. How to make sure API documentation is in sync with your code. How to serve internal documentation and keep it private.
Why documentation matters
One of the best questions you can ask a team before joining it, is whether it has any documentation. Just as dirty bathrooms in restaurants suggest a dirty kitchen, poor documentation in software companies suggests rusty software design and poor processes.
Content Preview
Photo by
Aaron Burden
Overview of tools and services to document your Python web application from installation instructions to public API. How to make sure API documentation is in sync with your code. How to serve internal documentation and keep it private.
Why documentation matters
One of the best questions you can ask a team before joining it, is whether it has any documentation. Just as dirty bathrooms in restaurants suggest a dirty kitchen, poor documentation in software companies suggests rusty software design and poor processes.
The goal of the architecture is to organize and constrain the dependencies between the components of your project. For example, in a regular Django project, views depend on models, and not vice versa. If you have utility functions, they shouldn’t depend on any specificities of your project.
I was playing with import-linter, and it looks promising.
What import-linter does
In Python projects, we define dependencies by imports. If module A imports module B, then A depends on B. import-linter lets you specify the rules that declaratively constrain that dependency flow. In a config file, you define so-called contracts. For example, one contract can say, “in my project, models.py must not have any imports from views.py.”
Content Preview
The goal of the architecture is to organize and constrain the dependencies between the components of your project. For example, in a regular Django project, views depend on models, and not vice versa. If you have utility functions, they shouldn’t depend on any specificities of your project.
In Python projects, we define dependencies by imports. If module A imports module B, then A depends on B. import-linter lets you specify the rules that declaratively constrain that dependency flow. In a config file, you define so-called contracts. For example, one contract can say, “in my project, models.py must not have any imports from views.py.”
If you work in a small company, chances are, your organization never had a dedicated role of a product manager. In startups, a product manager is one of the “hats” of the company’s founder. Founders use their vision and gut feelings to identify where the project should move. From a developer’s perspective, the role and the value of a product manager are not clear.
Content Preview
If you work in a small company, chances are, your organization never had a dedicated role of a product manager. In startups, a product manager is one of the “hats” of the company’s founder. Founders use their vision and gut feelings to identify where the project should move. From a developer’s perspective, the role and the value of a product manager are not clear.
Photo by Mihai Surdu
I often see seniors and veterans in the organization making two mistakes: talking when it’s time to listen and not knowing when to shut up. I am guilty as well, so here’s a memo for myself.
There’s a time to talk, and there’s a time to listen. If you’re familiar with the topic, you may feel a burning desire to jump in with your thoughts. Besides, if you are a veteran, the threshold for starting to talk is low for you. Catch yourself, take a pause. Wait longer, embrace the awkwardness of the moment. Invite a newcomer to the discussion. The barrier to begin speaking up is higher for a newcomer, but they provide a different perspective on a problem.
Content Preview
Photo by
Mihai Surdu
I often see seniors and veterans in the organization making two mistakes: talking when it’s time to listen and not knowing when to shut up. I am guilty as well, so here’s a memo for myself.
There’s a time to talk, and there’s a time to listen. If you’re familiar with the topic, you may feel a burning desire to jump in with your thoughts. Besides, if you are a veteran, the threshold for starting to talk is low for you. Catch yourself, take a pause. Wait longer, embrace the awkwardness of the moment. Invite a newcomer to the discussion. The barrier to begin speaking up is higher for a newcomer, but they provide a different perspective on a problem.
How often do your simple prototypes or ad-hoc scripts turn into fully-fledged applications?
The simplicity of organic code growth has a flip side: it becomes too hard to maintain. The proliferation of dicts as primary data structures is a clear signal of tech debt in your code. Fortunately, modern Python provides many viable alternatives to plain dicts.
What’s wrong with dicts?
Dicts are opaque
Functions that accept dicts are a nightmare to extend and modify. Usually, to change the function that takes a dictionary, you must manually trace the calls back to the roots, where this dict was created. There is often more than one call path, and if a program grows without a plan, you’ll likely have discrepancies in the dict structures.
Content Preview
How often do your simple prototypes or ad-hoc scripts turn into fully-fledged applications?
The simplicity of organic code growth has a flip side: it becomes too hard to maintain. The proliferation of dicts as primary data structures is a clear signal of tech debt in your code. Fortunately, modern Python provides many viable alternatives to plain dicts.
What’s wrong with dicts?
Dicts are opaque
Functions that accept dicts are a nightmare to extend and modify. Usually, to change the function that takes a dictionary, you must manually trace the calls back to the roots, where this dict was created. There is often more than one call path, and if a program grows without a plan, you’ll likely have discrepancies in the dict structures.
4 Reading mistakes I made
Published: Fri, 20 Nov 2020 07:41:05 +0000
Updated: Fri, 20 Nov 2020 07:41:05 +0000 UTC: 2020-11-20 07:41:05+00:00
URL: https://roman.pt/posts/reading-mistakes/
Photo by Giancarlo Duarte
My thoughts on how to become a better reader. The context is non-fiction books.
Not reading enough. I decided that there shouldn’t be a moment when I don’t have a book I’m reading. Also, I try not to have a day where I don’t read at least a bit. I know that people don’t like electronic books, but this is my primary way of reading. I always have a tab with the book I’m currently reading pinned in my browser. If I am tired and want to distract myself, I switch to that tab instead of opening a news site or a social feed.
Content Preview
Photo by
Giancarlo Duarte
My thoughts on how to become a better reader. The context is non-fiction books.
Not reading enough.
I decided that there shouldn’t be a moment when I don’t have a book I’m reading. Also, I try not to have a day where I don’t read at least a bit. I know that people don’t like electronic books, but this is my primary way of reading. I always have a tab with the book I’m currently reading pinned in my browser. If I am tired and want to distract myself, I switch to that tab instead of opening a news site or a social feed.
Thoughts on hiring and career planning as applied to software development.
Skills for sale
Imagine you can somehow measure your skills as you measure your weight.
In reality, of course, a single number doesn’t catch the multitude of nuances of your traits. An area can become a better representation of your skills. We usually call it “area of my expertise.” I call it amoeba to emphasize that it’s a living creature. It’s moving and growing.
Content Preview
Thoughts on hiring and career planning as applied to software development.
Skills for sale
Imagine you can somehow measure your skills as you measure your weight.
In reality, of course, a single number doesn’t catch the multitude of nuances of your traits. An area can become a better representation of your skills. We usually call it “area of my expertise.” I call it
amoeba
to emphasize that it’s a living creature. It’s moving and growing.
Python code cleanup for beginners. 12 steps to readable and maintainable code.
Photo by Lea Verou
It’s my responsibility to hire Python developers. If you have a GitHub account, I will check it out. Everyone does it. Maybe you don’t know, but your playground project with zero stars can help you to get that job offer.
The same goes for your take-home test task. You’ve heard this: when we meet a person for the first time, we make the first impression in 30 seconds, and this biases the rest of our judgment. I find it uncomfortably unfair that beautiful people get everything easier than the rest of us. The same bias applies to the code. You look at the project, and something immediately catches your eye. Leftovers of the old code in the repo, like leftovers of your breakfast in your beard, can ruin everything. You may not have a beard, but you get the point.
Content Preview
Photo by
Lea Verou
It’s my responsibility to hire Python developers. If you have a GitHub account, I will check it out. Everyone does it. Maybe you don’t know, but your playground project with zero stars can help you to get that job offer.
The same goes for your take-home test task. You’ve heard this: when we meet a person for the first time, we make the first impression in 30 seconds, and this biases the rest of our judgment. I find it uncomfortably unfair that beautiful people get everything easier than the rest of us. The same bias applies to the code. You look at the project, and something immediately catches your eye. Leftovers of the old code in the repo, like leftovers of your breakfast in your beard, can ruin everything. You may not have a beard, but you get the point.
Photo by Chris Montgomery
I use multitasking as a measure of the success of our regular team meetings.
If someone has time to reply to emails or finish their code during the meeting, then the topic doesn’t concern them, and it’s a waste of their time. It’s that easy.
The worst thing you can do here is to reprimand them. Saying that someone is not paying attention and you are disappointed is the reaction of a lousy school teacher. Effectively, you just got a very clear signal, but you prefer to ignore it and shoot the messenger. Instead, when I talk with my colleagues, I emphasize that multitasking is valuable information for the facilitator and a sign that it’s time to change something. I ask people to tell me if they catch themselves multitasking. Sometimes I even ask people directly how often they feel distracted at the team meetings.
Content Preview
Photo by
Chris Montgomery
I use multitasking as a measure of the success of our regular team meetings.
If someone has time to reply to emails or finish their code during the meeting, then the topic doesn’t concern them, and it’s a waste of their time. It’s that easy.
The worst thing you can do here is to reprimand them. Saying that someone is not paying attention and you are disappointed is the reaction of a lousy school teacher. Effectively, you just got a very clear signal, but you prefer to ignore it and shoot the messenger. Instead, when I talk with my colleagues, I emphasize that multitasking is valuable information for the facilitator and a sign that it’s time to change something. I ask people to tell me if they catch themselves multitasking. Sometimes I even ask people directly how often they feel distracted at the team meetings.
I’m a big fan of type hints, and I honestly don’t understand why some people find them ugly or unpythonic.
They improve the auto-complete and code navigation in the IDE.
They protect you against trivial errors and remind you about corner cases.
Beyond IDEs, more and more tools in the Python ecosystem take advantage of typing information. The FastAPI framework is the first example that comes to my mind.
They are like documentation that is testable, both human- and machine-readable, and never outdated.
They make you think about your code and highlight code smells. Do you need to return Optional, or is it better to implement a null object pattern? Do you need to return a Union or split your function in two?
Overall, they make explicit many implicit assumptions and connections in your code. Maybe people who complain that type hints are ugly fail to admit that type hints just uncover deficiencies of their own system?
Content Preview
I’m a big fan of type hints, and I honestly don’t understand why some people find them ugly or unpythonic.
They improve the auto-complete and code navigation in the IDE.
They protect you against trivial errors and remind you about corner cases.
Beyond IDEs, more and more tools in the Python ecosystem take advantage of typing information. The FastAPI framework is the first example that comes to my mind.
They are like documentation that is testable, both human- and machine-readable, and never outdated.
They make you think about your code and highlight code smells. Do you need to return Optional, or is it better to implement a null object pattern? Do you need to return a Union or split your function in two?
Overall, they make explicit many implicit assumptions and connections in your code. Maybe people who complain that type hints are ugly fail to admit that type hints just uncover deficiencies of their own system?
Accelerate. Five-minute summary
Published: Sat, 15 Aug 2020 13:28:00 +0100
Updated: Sat, 15 Aug 2020 13:28:00 +0100 UTC: 2020-08-15 12:28:00+00:00
URL: https://roman.pt/posts/accelerate/
A five-minute summary of the book “Accelerate: The Science of Lean Software and DevOps” by Nicole Forsgren, Jez Humble, and Gene Kim.
Photo by Ahmad Odeh
About the book
The overall idea of “Accelerate” is to find how engineering practices affect companies’ performance and the well-being of their employees.
This book feels like two books under the same cover. The first part, “What we found,” is practical, while the second, “The research,” explains in detail the science behind the book. Finally, there’s a third smaller part, “Transformation,” with a case study. I read the first part and only skimmed through the second and the third.
Content Preview
A five-minute summary of the book “Accelerate: The Science of Lean Software and DevOps” by Nicole Forsgren, Jez Humble, and Gene Kim.
The overall idea of “Accelerate” is to find how engineering practices affect companies’ performance and the well-being of their employees.
This book feels like two books under the same cover. The first part, “What we found,” is practical, while the second, “The research,” explains in detail the science behind the book. Finally, there’s a third smaller part, “Transformation,” with a case study. I read the first part and only skimmed through the second and the third.
Having a CI pipeline, running tests on every commit is not Continuous Integration.
Copying Open Source best practices to commercial development without understanding their context and limitations can be harmful.
Feature branches hinder refactoring.
Slow code reviews kill Continuous Integration, and it’s a common problem.
If you want CI, but can’t do fast code reviews, consider alternatives. Code reviews are the most common but not the only way to ensure the quality of the code.
Semantic conflicts
When you merge your changes back to the master branch, two types of conflicts may occur. Textual conflicts are those that prevent git from merging back your work without resolving them. Semantic conflicts are more subtle and harder to spot. An example of a semantic conflict is when one developer renames or moves a function, and another developer adds new calls for the old version of the function. It’s especially dangerous for Python, and without proper automated tests, unresolved semantic conflicts become runtime errors. To minimize the effect of the conflicts, Martin recommends integrating back your changes as often as possible. The rule of thumb is never to have branches that contain more than a day worth of changes.
Photo by Goran Ivos
Code ownership is a smell, and we need to avoid it. When several developers contribute to the same codebase, several great minds are thinking of the same problem, which eventually results in a better solution. On the opposite side of the spectrum, with strong code ownership, you inevitably end up with code that is easier to rewrite than to understand by others.
I took this for granted until I came across Microsoft research that contradicted my common sense. They showed that code ownership results in higher code quality and fewer bugs.
Content Preview
Photo by
Goran Ivos
Code ownership is a smell, and we need to avoid it. When several developers contribute to the same codebase, several great minds are thinking of the same problem, which eventually results in a better solution. On the opposite side of the spectrum, with strong code ownership, you inevitably end up with code that is easier to rewrite than to understand by others.
I took this for granted until I came across Microsoft research that contradicted my common sense. They showed that code ownership results in higher code quality and fewer bugs.
Photo by Dean Brierley
I shared our experience introducing feature flags in the tech ecosystem at Doist with our partners from CloudBees.
https://www.cloudbees.com/case-study/doist
CloudBees, known for rollout.io, asked us to share our case study, and it was a good opportunity to reflect on our journey towards feature-flag based development, what we’ve achieved so far, and where we’re heading. Also, it served as a reminder of how many different use cases such a simple idea unlocks.
Content Preview
Photo by
Dean Brierley
I shared our experience introducing feature flags in the tech ecosystem at Doist with our partners from CloudBees.
CloudBees, known for rollout.io, asked us to share our case study, and it was a good opportunity to reflect on our journey towards feature-flag based development, what we’ve achieved so far, and where we’re heading. Also, it served as a reminder of how many different use cases such a simple idea unlocks.
About me
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/about/
I’m a full-stack developer who builds things end to end. I’ve been doing this for almost 20 years, and what keeps me going is that the job keeps reinventing itself. The core stays the same: take an idea, figure out how to make it real, ship it, own the result.
The biggest recent shift in how I work is AI agents. I use Claude Code as my primary development environment, the actual driver of implementation. I focus on outcomes and keep the quality bar high, while the agent handles the path. I wrote about this in Claude Code as Your Execution Environment.
Content Preview
I’m a full-stack developer who builds things end to end. I’ve been doing this for almost 20 years, and what keeps me going is that the job keeps reinventing itself. The core stays the same: take an idea, figure out how to make it real, ship it, own the result.
The biggest recent shift in how I work is AI agents. I use Claude Code as my primary development environment, the actual driver of implementation. I focus on outcomes and keep the quality bar high, while the agent handles the path. I wrote about this in
Claude Code as Your Execution Environment
.
AWS
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/snippets/aws/
Go-to region
Use us-east-2 aka US East (Ohio).
Set up personal AWS profile to use
echo "export AWS_PROFILE=personal" >> .startup
Account info for your current requisites
aws sts get-caller-identity
Content Preview
Go-to region
Use
us-east-2
aka US East (Ohio).
Set up personal AWS profile to use
echo"export AWS_PROFILE=personal" >> .startup
Account info for your current requisites
aws sts get-caller-identity
Docker and docker-compose
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/snippets/docker/
Helpful services
composerize: convert docker run to docker-compose
Docker commands
Reclaim disk space
Clean up disk space by removing all the docker containers older than 14 days.
docker image prune -a --filter "until=336h"
See Prune unused Docker objects
Run a container and attach current directory
Example for a specific version of Python.
docker run -v $(pwd):/app --rm -it python:3.10 bash
Docker-compose Snippets
PostgreSQL
Sample docker-compose file to run a PostgreSQL server.
# The storage can be cleaned up by running the command:
# docker-compose down -v
#
# Django-environ settings:
# DATABASE_URL=psql://myproject:password@127.0.0.1:5499/myproject
version: '3.3'
services:
db:
image: postgres:14
environment:
POSTGRES_USER: myproject
POSTGRES_PASSWORD: password
POSTGRES_DB: myproject
ports:
- '127.0.0.1:5499:5432'
volumes:
- 'postgres-data:/var/lib/postgresql/data'
volumes:
postgres-data: {}
MongoDB
Sample docker-compose file to run a MongoDB server.
Content Preview
docker run -v $(pwd):/app --rm -it python:3.10 bash
Docker-compose Snippets
PostgreSQL
Sample docker-compose file to run a PostgreSQL server.
# The storage can be cleaned up by running the command:# docker-compose down -v## Django-environ settings:# DATABASE_URL=psql://myproject:password@127.0.0.1:5499/myprojectversion:'3.3'services:db:image:postgres:14environment:POSTGRES_USER:myprojectPOSTGRES_PASSWORD:passwordPOSTGRES_DB:myprojectports:- '127.0.0.1:5499:5432'volumes:- 'postgres-data:/var/lib/postgresql/data'volumes:postgres-data:{}
MongoDB
Sample docker-compose file to run a MongoDB server.
External links
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/links/
Timeless blog posts and articles. I found myself sharing these links over and over again, so I decided to put them here.
Software development
Questions on software development and the organization of team work.
Ship / Show / Ask. A modern branching strategy on how to relax the code review process without sacrificing quality.
Frequency reduces difficulty on why you need to deploy more often if the deployment is painful.
The Null Process on how the fear of introducing unnecessary processes can hurt your team.
Practical software architecture
Architecture solutions for real-world problems.
Content Preview
Timeless blog posts and articles. I found myself sharing these links over and over again, so I decided to put them here.
Software development
Questions on software development and the organization of team work.
The Null Process
on how the fear of introducing unnecessary processes can hurt your team.
Practical software architecture
Architecture solutions for real-world problems.
Git
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/snippets/git/
Delete merged branches
Leftovers from merged branches are distracting. Too many of them make commands like git branch -l useless. Here are some commands to clean them up.
Get the list of all branches that have been merged into the current branch.
git branch --merged
Delete all branches that have been merged into the current branch.
We exclude asterisk because that’s how we identify the current branch.
git_main_branch is an Oh My Zsh function that returns the name of the main branch.
git branch --merged "$(git_main_branch)" | grep -v "$(git_main_branch)" | grep -v '*' | xargs -n 1 git branch -d
See if there is anything left among unmerged branches.
Content Preview
Delete merged branches
Leftovers from merged branches are distracting. Too many of them make commands like
git branch -l useless
. Here are some commands to clean them up.
Get the list of all branches that have been merged into the current branch.
git branch --merged
Delete all branches that have been merged into the current branch.
We exclude asterisk because that’s how we identify the current branch.
git_main_branch
is an Oh My Zsh function that returns the name of the main branch.
See if there is anything left among unmerged branches.
Poetry
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/snippets/poetry/
Initialization
Quickly initialize a new Python environment with Poetry. We explicitly stick to Python 3.11.x (we don’t want automatic upgrades to 3.12, etc.). Also, we activate Poetry virtual environment on startup.
poetry init --python '~3.11' --no-interaction --quiet
poetry install
echo 'source $(poetry env info -p)/bin/activate' > .startup
Resolving rebase conflicts
When rebasing a branch with an updated poetry.lock, conflicts may arise. To resolve these conflicts, we can utilize the following function:
function poetry-resolve-rebase-conflict() {
git checkout --ours ./poetry.lock
poetry lock --no-update
git add ./poetry.lock
}
Content Preview
Initialization
Quickly initialize a new Python environment with Poetry. We explicitly stick to Python 3.11.x (we don’t want automatic upgrades to 3.12, etc.). Also, we activate Poetry virtual environment on startup.
frompydanticimport BaseModel
classModel(BaseModel):
"""Generic project-specific model."""classConfig:
# Allow field population by its name or alias# (helpful for mapping external API values) allow_population_by_field_name =TrueclassFrozenModel(BaseModel):
"""Generic project-specific frozen model."""classConfig:
# Make it frozen to allow using as dict keys frozen =True# Allow field population by its name or alias# (helpful for mapping external API values) allow_population_by_field_name =True
Integration with Arrow
importarrowclassPyArrow(arrow.Arrow):
"""FastAPI-serializable arrow instance."""@classmethoddef__get_validators__(cls):
yieldcls.validate
@classmethoddefvalidate(cls, v):
if v isNone:
raiseValueError("Invalid value")
return arrow.get(v)
@classmethoddef__modify_schema__(cls, field_schema):
field_schema.update(type="string")
FastAPI models
We want to return models with
camelCase
attributes, and we can automate it with Pydantic.
Here is a starter for a Python project. It can be used as the next step after creating the boilerplate with cookiecutter-python-project
Content Preview
Here is a starter for a Python project. It can be used as the next step after creating the boilerplate with
cookiecutter-python-project
python-dotenv for loading environment variables from
.env
and
.env.<environment>
files (e.g.,
.env.development
)
click for creating CLI commands
Optionally, IPython for interactive shell
File
myproject/config.py
"""Configuration.
The module doesn't depend on the project. The configuration file is initialized
with python-dotenv, and we don't read environment variables in the rest of the
project.
What config.py can import?
--------------------------
The module doesn't import anything from the project.
Who can import config.py?
---------------------------
The module is imported by the app.py to create services. It can also be imported in
the other parts of the application: for example, to get access to PROJECT_ROOT, or to
create project-specific services from requisites, provided in the config.
"""importosimportpathlibimportdotenvPROJECT_ROOT = pathlib.Path(__file__).parents[1]
ENVIRONMENT = os.getenv("ENVIRONMENT", "development")
config = {
**dotenv.dotenv_values((PROJECT_ROOT /".env").as_posix()),
**dotenv.dotenv_values((PROJECT_ROOT /f".env.{ENVIRONMENT}").as_posix()),
**os.environ,
}
# --------------------------------------------------------------------------------# Server configuration# --------------------------------------------------------------------------------HOST = config.get("HOST", "0.0.0.0")
PORT =int(config.get("PORT") or5000)
STATIC_ROOT ="/static"SECRET_KEY = config["SECRET_KEY"]
# --------------------------------------------------------------------------------# Sentry settings# --------------------------------------------------------------------------------# Set SENTRY_DSN to a non-empty value to enable Sentry.SENTRY_DSN = config.get("SENTRY_DSN")
SENTRY_ENVIRONMENT = config.get("SENTRY_ENVIRONMENT") or"development"
File
myproject/services.py
Quote of the Day Privacy Policy
Published: Mon, 01 Jan 0001 00:00:00 +0000
Updated: Mon, 01 Jan 0001 00:00:00 +0000 UTC: 0001-01-01 00:00:00+00:00
URL: https://roman.pt/apps/qod/privacy/
Privacy Policy
Roman Imankulov built the Quote of the Day app as a Free app. This SERVICE is provided by Roman Imankulov at no cost and is intended for use as is.
This page is used to inform visitors regarding my policies with the collection, use, and disclosure of Personal Information if anyone decided to use my Service.
If you choose to use my Service, then you agree to the collection and use of information in relation to this policy. The Personal Information that I collect is used for providing and improving the Service. I will not use or share your information with anyone except as described in this Privacy Policy.
Content Preview
Privacy Policy
Roman Imankulov built the Quote of the Day app as a Free app. This SERVICE is provided by Roman Imankulov at no cost and is intended for use as is.
This page is used to inform visitors regarding my policies with the collection, use, and disclosure of Personal Information if anyone decided to use my Service.
If you choose to use my Service, then you agree to the collection and use of information in relation to this policy. The Personal Information that I collect is used for providing and improving the Service. I will not use or share your information with anyone except as described in this Privacy Policy.